Difference between revisions of "Lezioni Anno Accademico 2016/17"
(→Lezione del 7 ottobre 2016: Inserito indice degli argomenti trattati.) |
|||
| (145 intermediate revisions by 8 users not shown) | |||
| Line 122: | Line 122: | ||
== Lezione del 7 ottobre 2016 == | == Lezione del 7 ottobre 2016 == | ||
| + | Audio Lezione: [https://drive.google.com/open?id=0B8G3NNuJ7MA7TzJXUTJZM3RBUlE 7\10\16] | ||
* '''Esempi di programmi in linguaggio C''' | * '''Esempi di programmi in linguaggio C''' | ||
| + | Abbiamo commentato i programmi dal 1.1 al 1.7 che si possono trovare in questa [[2016-17_Programmi_C|pagina]]. | ||
* '''Economia Push/Economia Pull''' | * '''Economia Push/Economia Pull''' | ||
| − | * '''Sistemi Operativi e parallelismo ( | + | Nell'economia push si basa la produzione sulla previsione di domanda e la si cerca di aumentare tramite la pubblicità. Questa è stata la principale metodologia utilizzata nei secoli scorsi. |
| + | Al giorno d'oggi si sta facendo avanti un differente approccio chiamato "economia pull" dove la produzione è basata sulla domanda effettiva. Per esempio per richiedere un finanziamento per l'economia push l'approccio comune è tramite una banca a cui si chiede un prestito in base alle previsioni di ricavo. Invece nell'economia pull è esemplare il fenomeno del crowdfounding dove si riceve un finanziamento dalla "folla" cioè da un gruppo di persone che dona una piccola parte di denaro ciascuna in base al reale interesse per il prodotto/servizio. | ||
| + | * '''Sistemi Operativi e parallelismo''' | ||
| + | Più processi si dicono in esecuzione concorrente quando accedono a risorse condivise. | ||
| + | Un programma è multithread quando tutti i thread condividono la stessa memoria. Ogni thread deve avere un suo stack. | ||
| + | La concorrenza si studia in particolare in sistemi operativi in quanto un sistema operativo multitasking è un sistema concorrente. | ||
| + | Concorrenza di processi in architetture SMP (Symmetric multiprocessor system) e non. (RD: non mi pare di aver spiegato cosa sia l'SMP) <br> | ||
| + | Simulazione del fenomeno della '''race condition'''. Si ha '''race condition''' quando un programma concorrente può puo' produrre diversi risultati se eseguito piu' volte per colpa della diversa evoluzione temporale delle elaborazioni.<br> | ||
| + | Per risolvere questo dovremmo raggruppare le istruzioni in ''sezioni critiche'' (sequenze inscindibili di istruzioni che devono essere eseguite come se fossero atomiche, tutta la sequenza o niente). | ||
* '''Architettura a livelli e virtualizzazione''' | * '''Architettura a livelli e virtualizzazione''' | ||
| + | Dato un A e un A’ e riusciamo a usare A’ come A, allora A’ lo possiamo chiamare A virtuale. | ||
| + | L'idea che alla base delle macchine virtuali è di creare un interprete di un ISA differente o uguale a quello del sistema in modo da virtualizzare una reale macchina hardware e quindi poterla usare per gli stessi scopi di una macchina reale. E' quindi possibile, per esempio, installare sistemi operativi su hardware virtuale.<br> | ||
| + | L'insieme dei componenti hardware virtuali e il software installato su di questi prende il nome di ''macchina virtuale''. | ||
| + | Uno dei principali vantaggi, oggi molto utilizzato in ambito cloud, è quello di poter suddividere facilmente risorse hardware fisiche, per esempio spazio su disco e potenza di elaborazione, tra macchine virtuali differenti. | ||
* '''Laboratorio di cross-compiling''' | * '''Laboratorio di cross-compiling''' | ||
| + | Nel ultima parte della lezione abbiamo fatto un esperimento sulla portabilità dei compilatori. <br> | ||
| + | Abbiamo a disposizione un linguaggio ad alto livello che chiameremo L, due interpreti hw0 e hw1 per linguaggi a basso livello che chiameremo lhw0 e lhw1 e infine due compilatori L->lhw0 uno scritto in python e l'altro in L. <br> | ||
| + | Se compiliamo con il compilatore scritto in python (abbiamo un interprete python installato sulla macchina che stiamo utilizzando) il compilatore scritto in L otteniamo un compilatore scritto in lhw0 L->lhw0. <br> | ||
| + | Se ora modifichiamo il compilatore scritto in L L->lhw0 in modo che crei codice per hw1 (basta modificare gli indici numerici delle istruzioni) otteniamo un compilatore in L L->lhw1. Se lo compiliamo con il compilatore L->lhw0 otteniamo un ''cross-compiler'' scritto in lhw0 L->lhw1, cioè un compilatore che crea codice eseguibile su una macchina diversa da quella attuale. <br> | ||
| + | Se ora utilizziamo il cross compiler L->lhw1 per compilare il compilatore scritto in L L->hw1 otteniamo invece un compilatore che può essere eseguito su hw1. <br> | ||
| + | A questo punto su hw1 potremmo utilizzare l'ultimo compilatore creato per compilare sempre il compilatore scritto in L L->hw1 ma vedremo che otterremo sempre lo stesso file perché avremo raggiunto il limite. | ||
| + | <br> | ||
| + | Il materiale per poter replicare l'esperimento sulla portabilità dei compilatori è [http://www.cs.unibo.it/~renzo/so/tools/portability3.tgz qui]. | ||
| + | [[User:Renzo|Renzo]] ([[User talk:Renzo|talk]]) 13:42, 8 October 2016 (CEST) | ||
== Lezione del 11 ottobre 2016 == | == Lezione del 11 ottobre 2016 == | ||
| + | *'''C''' | ||
| + | <syntaxhighlight lang=C> | ||
| + | #include <stdio.h> | ||
| + | |||
| + | void dump (void* f, size_t len){ //size_t is the sizeof() return type | ||
| + | unsigned char *s = f; | ||
| + | size_t i; | ||
| + | for (i = 0; i < len; i++) | ||
| + | printf("%02x ",s[i]); //%02x means print at least 2 digits and add 0's if there are less | ||
| + | printf("\n"); | ||
| + | } | ||
| + | |||
| + | int main(){ | ||
| + | |||
| + | int v[] = {1, 2, 3, 4}; //v is (int*) 0x32ef... | ||
| + | v[2] = 42; //*((int*) 0x32ef) + 2 = 42, moves the address by 2 "positions", aka 4+4 bytes | ||
| + | v[2] = 0x33;//(int*) 0x32ef.. = 0x33 (i.e.) 4 = 42 | ||
| + | |||
| + | char s[] = "ciao"; | ||
| + | int t[] = {0x63, 0x69, 0x61, 0x6f, 0x00}; //ciao in ASCII hex. if int OUT:'c'. if char OUT:"ciao" | ||
| + | char u[] = {99, 105,97, 111, 0 }; //ciao in ASCII dec. OUT:"ciao" | ||
| + | |||
| + | char *q = "ciao"; | ||
| + | char *w = "mare"; | ||
| + | |||
| + | printf("%s\n", s); | ||
| + | printf("%s\n", t); | ||
| + | printf("%s\n", u); | ||
| + | |||
| + | dump(s, sizeof(s)); | ||
| + | dump(t, sizeof(t)); | ||
| + | dump(q, sizeof(*q)); //*q size is 1B (it points to 1 char). OUT: 63('c') | ||
| + | dump(q, sizeof(q)); //q size is 8B. OUT: 5B of "ciao" + 3B of contiguous string "mare" | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
| + | OUTPUT: | ||
| + | <pre> | ||
| + | ciao | ||
| + | c | ||
| + | ciao | ||
| + | 63 69 61 6f 00 | ||
| + | 63 00 00 00 69 00 00 00 61 00 00 00 6f 00 00 00 00 00 00 00 //int are 4B, char 1B, so we have empty bytes. | ||
| + | Little endian pattern is evident. %s allow to print untill the first null, so printf prints just 'c' with int declaration of t[] | ||
| + | 63 | ||
| + | 63 69 61 6f 00 6d 61 72 // 6d = m, 61 = a, 72 = r. | ||
| + | </pre> | ||
| + | |||
| + | * '''Assioma di finite progress.''' | ||
| + | "Tutto è vero purchè ogni statement abbia durata sconosciuta, ma finita" | ||
| + | * '''Modalità di concorrenza.''' | ||
| + | 1- Inconsapevolmente concorrenti: ogni processo elabora ciò per cui è stato creato. Il kernel si occupa di coordinazione e comunicazione. | ||
| + | |||
| + | 2- Indirettamente concorrenti: processi che accedono a file condivisi. | ||
| + | |||
| + | 3- Consapevolmente concorrenti: il programma ha diversi processi in esecuzione. | ||
| + | *''' Convenzioni usate nel corso (e negli esami) relative alle istruzioni atomiche''' | ||
| + | Le istruzioni atomiche vengono compiute in modo indivisibile, garantendo che l'azione non interferisca con altri processi durante la sua esecuzione. | ||
| + | Vengono rappresentate nel seguente modo: | ||
| + | <pre> | ||
| + | <istruzione atomica> | ||
| + | </pre> | ||
| + | Anche gli statement sono istruzioni atomiche(escluso il caso long long). | ||
| + | *''' Proprieta' di Safety e Liveness''' | ||
| + | -Safety: se il programma evolve, evolve bene(S) | ||
| + | |||
| + | "''Something good'' happens" | ||
| + | |||
| + | -Liveness: il programma va avanti(L) | ||
| + | |||
| + | "''Something eventually'' happens" | ||
| + | |||
| + | * '''Problema del consenso.''' | ||
| + | Il problema è così definito: ci sono n processi, ognuno propone un valore. Al termine tutti i processi devono accordarsi su di 1 dei valori proposti.Il suddetto problema è risolvibile se e solo se vengono rispettate le seguenti proprietà (2 di Safety + 1 di Liveness) | ||
| + | |||
| + | Proprietà: | ||
| + | |||
| + | S(1)- Tutti i processi devono ritornare lo stesso valore | ||
| + | |||
| + | S(2)- Ogni processo corretto decide uno tra i valori proposti | ||
| + | |||
| + | L(1)- Ogni processo corretto deve dare una risposta | ||
| + | |||
| + | w/o S(1): f(x) = x | ||
| + | |||
| + | w/o S(2): f(x) = 42 | ||
| + | |||
| + | w/o L(1): f(x) = while(1) | ||
| + | |||
| + | *w/o = without | ||
| + | |||
| + | * '''Problemi delle elaborazioni concorrenti. Prima definizione (non formale) di Deadlock e Starvation''' | ||
| + | Introduzione alla notazione per la rappresentazione dei processi concorrenti | ||
| + | |||
| + | ESEMPIO 1.0 | ||
| + | |||
| + | process p { | ||
| + | ... | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q { | ||
| + | ... | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | Due processi eseguiti in concorrenza. | ||
| + | |||
| + | ... | ||
| + | cobegin | ||
| + | ... | ||
| + | // | ||
| + | ... | ||
| + | // | ||
| + | ... | ||
| + | coend | ||
| + | |||
| + | cobegin e coend indicano la sezione di codice con le istruzioni (rappresentate da "..." e separate da "//")che verranno eseguite in concorrenza. | ||
| + | |||
| + | ESEMPIO 1.1 - Merge sort | ||
| + | cobegin | ||
| + | sort(v[1 : N]) | ||
| + | // | ||
| + | sort(v[N : N]) | ||
| + | // | ||
| + | merge(v[1 : N]), v[N : M]) | ||
| + | coend | ||
| + | |||
| + | Se isoliamo le istruzioni senza considerare cobegin e coend, lo pseudocodice è corretto. | ||
| + | Se consideriamo anche cobegin e coend il programma esegue la funzione di merge() in concorrenza con le due chiamate a sort(), utilizzando risorse in comune e pertanto cercando di ordinare elementi non ancora ordinati nelle due metà dell'array. | ||
| + | Se spostiamo l'invocazione di merge al di fuori della sezione cobegin ... coend, lo pseudocodice (vedi in basso) è corretto. | ||
| + | |||
| + | cobegin | ||
| + | sort(v[1 : N]) | ||
| + | // | ||
| + | sort(v[N : N]) | ||
| + | coend | ||
| + | merge(v[1 : N]), v[N : M]) | ||
| + | |||
| + | |||
| + | |||
| + | In particolare nella programmazione concorrente si devono affrontare due problemi che riguardano la liveness, parliamo di deadlock e starvation. | ||
| + | |||
| + | '''DEADLOCK''': uno o più processi non possono continuare l'esecuzione perchè ognuno di essi è in attesa che gli altri facciano qualcosa | ||
| + | |||
| + | ESEMPIO 1.2 | ||
| + | |||
| + | process p { | ||
| + | while 1: | ||
| + | prendi a | ||
| + | prendi b | ||
| + | calcola f(a,b) | ||
| + | lascia a | ||
| + | lascia b | ||
| + | } | ||
| + | |||
| + | process q { | ||
| + | while 1: | ||
| + | prendi a | ||
| + | prendi b | ||
| + | calcola f(a,b) | ||
| + | lascia a | ||
| + | lascia b | ||
| + | } | ||
| + | |||
| + | Supponiamo di invertire l'ordine di prendi a e prendi b nel processo p. Dopo che entrambi i processi eseguono la prima istruzione lo scenario che si sviluppa è il seguente: al processo p serve la risorsa a, presa dal processo q, al quale servirebbe la risorsa b, presa dal processo p. I processi aspettano a vicenda che uno rilasci la risorsa che possiede l'altro. Risorsa necessaria ad entrambi i processi per eseguire l'istruzione (f(a,b)) che le richiederebbe entrambe. I processi sono deadlocked. | ||
| + | |||
| + | |||
| + | '''STARVATION''': quando un processo attende una risorsa indefinitamente, e questa non gli viene mai allocata | ||
| + | |||
| + | ESEMPIO 1.3 | ||
| + | process p { | ||
| + | while 1: | ||
| + | prendi a | ||
| + | calcola f(a) | ||
| + | lascia a | ||
| + | } | ||
| + | |||
| + | process q { | ||
| + | while 1: | ||
| + | prendi a | ||
| + | calcola f(a) | ||
| + | lascia a | ||
| + | } | ||
| + | |||
| + | Supponiamo che i processi per realizzare "prendi a" verifichino la disponibilità di a tramite polling (provando ripetutamente se a è libero). Il processo q può essere sfortunato e non riuscire mai ad avere accesso ad a (tutte le volte che cerca di "prenderlo" lo troverà impegnato da p). Il processo q è in starvation. | ||
| + | |||
| + | ESEMPIO 1.4 | ||
| + | "Supponiamo di avere tre processi (P1, P2, P3) i quali richiedono periodicamente accesso alla risorsa R. Consideriamo la situazione nella quale P1 è in possesso della risorsa, e sia P2 che P3 attendono per quella risorsa. Quando P1 esce dalla sua sezione critica, a P2 o P3 dovrebbe essere permesso l'accesso a R. Assumiamo che il SO garantisca l'accesso a P3 e che P1 richieda nuovamente la risorsa prima che P3 termini la sua sezione critica. Se il SO dovesse garantire l'accesso a P1 dopo che P3 abbia finito, e successivamente dovesse garantire alternativamente a P1 e P3 l'accesso alla risorsa, allora P2 potrebbe vedersi indefinitamente negato l'accesso alla risorsa, sebbene non vi sia una situazione di deadlock" (Stallings W.(2015). ''Operating System: internals and design principles''. (8th ed). Pearson) | ||
| + | |||
| + | |||
| + | '''Problema: posso creare sezioni critiche, tramite la programmazione, senza aiuti hardware?''' | ||
| + | |||
| + | ESEMPIO | ||
| + | |||
| + | process p | ||
| + | /*enter_cs*/ | ||
| + | A = A + 1 | ||
| + | /*exit_cs*/ | ||
| + | |||
| + | process q | ||
| + | /*enter_cs*/ | ||
| + | A = A - 1 | ||
| + | /*exit_cs*/ | ||
| + | |||
| + | '''Le 4 proprietà della critical section(CS)''' | ||
| + | |||
| + | SAFETY(1): una operazione all'interno della CS | ||
| + | |||
| + | ESEMPIO | ||
| + | process p | ||
| + | while 1: | ||
| + | /*enter_cs*/ | ||
| + | A = A + 1 | ||
| + | /*exit_cs*/ | ||
| + | ... <--- process q deve poter "entrare" qui | ||
| + | |||
| + | LIVENESS(1): no deadlock | ||
| + | |||
| + | LIVENESS(2): no starvation | ||
| + | |||
| + | LIVENESS(3): no useless wait | ||
| + | |||
| + | |||
| + | ''Dekker(1st attempt) //KEY: turno'' | ||
| + | |||
| + | turn = p //var globale condivisa | ||
| + | |||
| + | process p{ | ||
| + | while (turn != p) | ||
| + | ; | ||
| + | /*A = A + 1*/ | ||
| + | turn = q | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q{ | ||
| + | while(turn != q) | ||
| + | ; | ||
| + | /*A = A - 1*/ | ||
| + | turn = p | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | Non rispetta la proprietà di liveness(3), infatti uno dei due processi può dover attendere a lungo il suo turno eseguendo ciclicamente l'empty statement all'interno | ||
| + | del corpo del while. Questa situazione può verificarsi se l'altro processo fallisce dentro o fuori la sua CS (in questo caso l'attesa è infinita). Inoltre visto che i processi si alternano strettamente nell'utilizzo della loro critical section, il ritmo di esecuzione è dettato dal processo più lento dei due. | ||
| + | |||
| + | ''Dekker(2nd attempt) //KEY: flag, ma senza turno'' | ||
| + | |||
| + | inp = false | ||
| + | |||
| + | inq = false | ||
| + | |||
| + | process p{ | ||
| + | while 1: | ||
| + | while(inq) | ||
| + | ; | ||
| + | inp = true | ||
| + | /*A = A + 1*/ | ||
| + | inp = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q{ | ||
| + | while 1: | ||
| + | while(inp) | ||
| + | ; | ||
| + | inq = true | ||
| + | /*A = A - 1*/ | ||
| + | inq = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | In questo caso se uno dei processi fallisce fuori dalla CS (dopo aver settato il flag a false) l'altro processo non viene bloccato. Se invece un processo fallisce nella sua CS oppure dopo aver settato il flag a true allora l'altro processo resta bloccato indefinitamente. Non è garantita inoltre la mutua esclusione in quanto entrambi potrebbero essere al contempo nelle loro rispettive CS, ad esempio: | ||
| + | |||
| + | p valuta la condizione del while e trova inq a false | ||
| + | |||
| + | q valuta la condizione del while e trova inp a false | ||
| + | |||
| + | p assegna true a inp ed entra nella sua CS | ||
| + | |||
| + | q assegna true a inq ed entra nella sua CS | ||
| + | |||
| + | ....entrambi sono nella rispettiva CS --> no liveness(1) | ||
| + | |||
| + | ''Dekker(3nd attempt) //KEY: come 2nd ma con due istruzioni scambiate di ordine'' | ||
| + | |||
| + | process p{ | ||
| + | while 1: | ||
| + | inp = true | ||
| + | while(inq) | ||
| + | ; | ||
| + | /*A = A + 1*/ | ||
| + | inp = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q{ | ||
| + | while 1: | ||
| + | inq = true | ||
| + | while(inp) | ||
| + | ; | ||
| + | /*A = A - 1*/ | ||
| + | inq = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | Scambiando l'ordine di due istruzioni vi è la mutua esclusione, tuttavia se entrambi i processi assegnano true al loro rispettivo flag, prima di valutare la condizione | ||
| + | del while, entrambi resteranno all'interno del while in attesa che l'altro processo "esca dalla CS" (non vi è mai entrato) --> deadlock | ||
| + | |||
| + | ''Dekker(4nd attempt) //KEY: flag + delay'' | ||
| + | |||
| + | process p{ | ||
| + | while 1: | ||
| + | inp = true | ||
| + | while(inq){ | ||
| + | inp = false; < delay >; inp = true; | ||
| + | } | ||
| + | /*A = A + 1*/ | ||
| + | inp = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q{ | ||
| + | while 1: | ||
| + | inq = true | ||
| + | while(inp){ | ||
| + | inq = false; < delay >; inq = true; | ||
| + | } | ||
| + | /*A = A - 1*/ | ||
| + | inq = false | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | In questo caso il settare il proprio flag a true è indice del desiderio di entrare nella propria CS. Vi è ancora mutua esclusione. Se però dovesse verificarsi una sequenza del tipo: | ||
| + | |||
| + | p imposta flag inp a true | ||
| + | |||
| + | q imposta falg inq a true | ||
| + | |||
| + | p valuta la condizione del while | ||
| + | |||
| + | q valuta la condizione del while | ||
| + | |||
| + | p imposta flag inp a false | ||
| + | |||
| + | q imposta flag inq a false | ||
| + | |||
| + | p imposta flag inp a true | ||
| + | |||
| + | q imposta flag inq a true | ||
| + | |||
| + | allora c'è la possibilità che si ripeta all'infinito (entrambi i processi potrebbero rimanere nel while). Essendo però una condizione che dipende dalla velocità relativa dei due processi, esiseranno delle situazioni nelle quali uno dei due processi potrà entrare, così come vi saranno delle situazioni nelle quali nessun processo avrà accesso alla propria CS --> livelock | ||
| + | |||
| + | '''Dekker...finally //KEY: flag + turni ("cambio delay con turno)''' | ||
| + | |||
| + | needp = false | ||
| + | |||
| + | needq = false | ||
| + | |||
| + | turn = p | ||
| + | |||
| + | process p{ | ||
| + | while 1: | ||
| + | needp = true | ||
| + | while (needq) { | ||
| + | needp = false | ||
| + | while(turn == q) | ||
| + | ; | ||
| + | needp = true | ||
| + | } | ||
| + | /*A = A + 1*/ | ||
| + | needp = false | ||
| + | turn = q | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | process q{ | ||
| + | while 1: | ||
| + | needq = true | ||
| + | while(needp) { | ||
| + | needq = false; | ||
| + | while(turn == p) | ||
| + | ; | ||
| + | needq = true | ||
| + | } | ||
| + | /*A = A - 1*/ | ||
| + | needq = false | ||
| + | turn = p | ||
| + | ... | ||
| + | } | ||
| + | |||
| + | In questo caso il processo che vuole entrare nella sua CS ne manifesta il bisogno settando need a true. Se entrambi i processi entrano nel corpo del while il tie-break è espletato dal while la cui condizione è un turn che sarà uguale soltanto ad uno dei due processi (in questo caso turn è inizializzata a p), e dunque non si verificherànno situazioni di deadlock o livelock. | ||
| + | *'''Proprietà della sezione critica''' | ||
| + | Mutua esclusione <br> | ||
| + | Assenza di deadlock <br> | ||
| + | Assenza di starvation <br> | ||
| + | Assenza di delay non necessari | ||
| + | |||
| + | *'''La test&set''' | ||
| + | E' un istruzione atomica per impostare il valore di una variabile a 1 (lock) ma ritornare il vecchio valore. Questa istruzione può essere utilizzata per gestire sezioni critiche. <br> | ||
| + | Il valore ritornato dalla test and set viene comparato a 1, se è uguale si aspetta altrimenti si procede.<br> | ||
| + | In questo modo il primo processo che cercherà di entrare nella sezione critica ci riuscirà e imposterà il lock a 1, gli altri processi si troveranno il lock a 1 e dovranno aspettare. Quando il primo processo avrà finito ripristinerà il vecchio valore di lock e permetterà a uno degli altri processi di eseguire la test and set e di entrare nella sezione critica. | ||
| + | ---- | ||
| + | Altri argomenti trattati che non sono stati qui riportati in forma di appunti: | ||
| + | Gestione algoritmica della critical section. | ||
| + | Algoritmo di Dekker. | ||
| + | Gestione architetturale della critical section. | ||
| + | |||
| + | [[User:Renzo|Renzo]] ([[User talk:Renzo|talk]]) 10:35, 17 October 2016 (CEST) | ||
| + | |||
== Lezione del 14 ottobre 2016 == | == Lezione del 14 ottobre 2016 == | ||
| + | Audio Lezione: [https://drive.google.com/open?id=0B8G3NNuJ7MA7UlJadTRVbzhWRFE 14\10\16] | ||
| + | * Sistemi Operativi per elaboratori multiprocessore SMP/non SMP | ||
| + | * Macchine di von Neumann (e di Harvard). | ||
| + | * Il bus. | ||
| + | * Interrupt e Trap | ||
| + | * Gestione degli interrupt | ||
| + | * Mascheramento degli interrupt | ||
| + | * Interrupt Nidificati | ||
| + | * DMA | ||
| + | * Device a carattere e device a blocchi | ||
| + | * System call come trap. | ||
| + | * La gerarchia delle memorie | ||
| + | * cache | ||
| + | |||
== Lezione del 18 ottobre 2016 == | == Lezione del 18 ottobre 2016 == | ||
| + | Audio Lezione: [https://drive.google.com/open?id=0B8G3NNuJ7MA7eVlFdWR0cUkxd2M 18/10/16] | ||
| + | |||
| + | Argomenti trattati: | ||
| + | *'''Implementazione in C della Test&Set, degli Algoritmi di Dekker e Peterson.''' | ||
| + | Codice sorgente disponibile [[Dekker,_Peterson_e_Test%26Set_in_C|qui]]. | ||
| + | *'''Definizione di Semaforo.''' | ||
| + | Un semaforo è una variabile intera che può essere modificata solo da 2 operazioni atomiche: P(Proberen) e V(Verhogen).<br> | ||
| + | P aspetta che il valore sia minore o uguale a zero. Quando lo diventa decrementa il valore.<br> | ||
| + | S incrementa il valore. <br> | ||
| + | *'''Invariante del Semaforo.''' | ||
| + | Il numero di Proberen deve essere minore o uguale al numero di Verhogen più il valore d'inizializzazione del semaforo. <br> | ||
| + | In questo modo si può gestire per esempio l'allocazione di risorse. Il semaforo viene inizializzato al numero di risorse e ogni volta che un processo ha bisogno della risorsa esegue un proberen, quindi decrementa il valore se la risorsa è disponibile. Quando un processo rilascia la risorsa esegue un verhogen. | ||
| + | *'''Esempio: implementazione di sezione critica e di semplice sincronizzazione con semafori.''' | ||
| + | |||
== Lezione del 21 ottobre 2016 == | == Lezione del 21 ottobre 2016 == | ||
| + | *'''Make''' | ||
| + | Make è un sistema per la compilazione intelligente dei programmi. <br> | ||
| + | Permette invece di compilare tutto il programma tutte le volte di compilarne solo una parte, solo quella che è stata modificata. | ||
| + | Per capirne il funzionamento è utile un parallelismo con le ricette di cucina. Si specificano dei target che sono gli obbiettivi della ricetta.Per fare una ricetta servono degli ingredienti e magari quegli ingredienti hanno a loro volta delle ricette. Make allo stesso modo definisce dei target che possono avere come dipendenze altri target. <br> | ||
| + | Nel installazione del programma il programma ./configure cerca nel sistema se le librerie da cui è dipendente il programma sono presenti. <br> | ||
| + | *'''Git''' | ||
| + | Git è un sistema di versioning, serve a tener traccia delle modifiche apportante a un progetto nel tempo. E' utile per collaborare a un progetto condiviso. <br> | ||
| + | Possibilità per ogni membro del repository di lavorare in maniera indipendente e poi aggiornare il progetto comune. <br> | ||
| + | Ce ne sono stati tanti di sistemi di versioning tipo SVN, Mercurial ma attualmente Git è il più utilizzato.<br> | ||
| + | Git non serve solo per scrivere programmi ma per esempio anche libri, in modo collaborativo.<br> | ||
| + | Git è completamente distribuito, non esiste in un repository una copia principale e delle copie secondarie ma ogni copia può essere principale. <br> | ||
| + | Per iniziare un repository git si utilizza il comando ''git init''.<br> | ||
| + | Per aggiungere un file al repository si utilizza il comando ''git add''.<br> | ||
| + | Ma ad ogni singola modifica git non aggiorna automaticamente il repository ma è l'utente che tramite il comando git commit indica che una certa versione del progetto deve essere salvata.<br> | ||
| + | Il comando ''git log'' serve a visualizzare la storia del repository.<br> | ||
| + | Il comando ''git diff'' serve a vedere la differenza tra ciò che è nel repository e le modifiche di cui non si è ancora fatto il commit.<br> | ||
| + | Dopo aver dato il comando add si dice che i file sono 'on stage' prima del commit.<br> | ||
| + | Il comando ''git checkout'' serve a spostarsi nella storia del repository.<br> | ||
| + | Il comando ''git clone'' serve a copiare un repository remoto.<br> | ||
| + | Il comando ''git push'' serve a inviare le modifiche al repository remoto mentre il comando ''git pull'' serve a ricevere le modifiche più aggiornate dal repository remoto.<br> | ||
| + | Il ''merge'' è il processo in cui uno degli utenti che crea un conflitto deve "a mano" scegliere quali parti dei due commit in conflitto vuole tenere.<br> | ||
| + | Git è utile per trovare i bug che non erano presenti in versioni precedenti del progetto. Si può tornare alla versione precedente stabile e avanzare nella storia fino a trovare una versione instabile. A questo punto è probabile che l'origine del bug sia nelle modifiche che hanno creato questa versione instabile.<br> | ||
| + | Github è una piattaforma di repository dove possono essere mantenuti dei progetti gratuitamente se sono con licenza libera.<br> | ||
| + | In una directory in cui è presente un repository git e sempre la presente la cartella ''.git'' dove il sistema di versioning mantiene il database della storia. <br> | ||
| + | |||
== Lezione del 25 ottobre 2016 == | == Lezione del 25 ottobre 2016 == | ||
| + | Audio Lezione: [https://drive.google.com/open?id=0B8G3NNuJ7MA7WjZJMm11cjhuQXc 25/10/16] | ||
| + | |||
| + | Argomenti trattati: | ||
| + | * '''Semafori fair''' | ||
| + | Un semaforo è "fair" quando tende a non sbloccare dallo stato di attesa sempre lo stesso processo ma cerca di distribuire la possibilità di esecuzione a più processi. | ||
| + | * '''Problemi classici della concorrenza risolti con semafori''' | ||
| + | ** '''Produttore/consumatore''' | ||
| + | ::Due processi: produttore e consumatore. Il produttore genera continuamente dei valori e il consumatore continuamente li legge. Il consumatore deve leggere i valori nello stesso ordine in cui il produttore li genera. <br> | ||
| + | ::Un meccanismo di sincronizzazione e richiesto perchè sorgono immediatamente due problemi: | ||
| + | ::* Produttore troppo veloce: il consumatore non fa in tempo a consumare il valore e c'è la possibilità che i valori non ancora letti vengano sovrascritti. | ||
| + | ::* Consumatore troppo veloce: possibilità che il consumatore legga un valore che ha già letto perchè il produttore non ha fatto in tempo a produrne uno nuovo. | ||
| + | ::Per risolvere il problema utilizziamo due semafori: empty e full. <br> | ||
| + | ::Il produttore aspetta che il segnale del semaforo empty (Proberen), scrive il valore e dà segnale sul semaforo full (Verhogen).<br> | ||
| + | ::Il consumatore aspetta il segnale del semaforo full (Proberen), legge il valore e dà segnale sul semaforo empty (Verhogen).<br> | ||
| + | :* '''Buffer-limitato''' | ||
| + | ::Simile al problema produttore/consumatore ma qui lo scambio avviene tramite un buffer limitato. <br> | ||
| + | ::In questo modo nel caso di rallentamento temporaneo del consumer il producer non deve aspettare ma può produrre più unità e viceversa nel caso di rallentamento del producer, se il buffer ha più di un elemento, il consumer può utilizzare il tempo in attesa del producer per consumare più dati. <br> | ||
| + | ::Nel caso il buffer sia completamente pieno/vuoto rimangono comunque i problemi di sincronizzazione tipici del problema: il producer non deve sovrascrivere dei valori che il consumer non ha ancora letto e il consumer non deve leggere più volte lo stesso valore se il producer non è stato abbastanza veloce da cambiarlo. <br> | ||
| + | ::Come soluzione al problema si può utilizzare un coda circolare. Il produttore esegue una enqueue e il consumatore una dequeue. <br> | ||
| + | ::Il problema può essere generalizzato facilmente a produttori/consumatori multipli ma in questo caso dobbiamo creare un semaforo per rendere atomiche la enqueue e la dequeue altrimenti incorriamo in una race condition nel accesso alla coda. | ||
| + | |||
== Lezione del 28 ottobre 2016 == | == Lezione del 28 ottobre 2016 == | ||
| − | + | ||
| + | '''Implementazione dei semafori''' <br> | ||
| + | Un processo che esegue una Proberen in teoria dovrebbe aspettare continuando a controllare se può entrare nella sezione critica. Questo meccanismo si chiama "busy waiting" e consuma molte istruzioni della CPU. <br> | ||
| + | Il busy waiting è diverso dal polling in quando il polling prevede di eseguire altre azioni mentre si aspetta tra un tentativo e l'altro. <br> | ||
| + | Di solito si utilizza il busy waiting solo quando il tempo di lock di un processo è molto breve. Questo perchè anche se esoso di risorse del processore il busy waiting non comporta un context switch, cioè salvare tutto lo stato del processo in memoria, e quindi permette di risparmiare memoria. | ||
| + | Se invece il tempo di lock è più lungo allora è preferibile utilizzare un context-switch dove il processo si blocca da solo e chiama un processo di blocking che lo mette in una coda di attesa associata al semaforo che sta aspettando. Il controllo passa poi allo scheduler della CPU che seleziona un altro processo da eseguire. | ||
| + | Le primitive suspend and wakeup indicano rispettivamente lo spostamento di un processo nella/dalla coda dei processi ready. | ||
| + | * nei kernel monoprocessore | ||
| + | : Implementazione dei semafori tramite mutex che possono essere a loro volta implementate con un sistema di mascheramento degli interrupt. | ||
| + | * nei kernel multiprocessore | ||
| + | : Utilizzo di soluzioni hardware come test and set. Sono soluzioni che utilizzano il busy waiting ma in questo caso solo per rendere atomico le operazioni del semaforo, che sono poche istruzioni. | ||
| + | Certe implementazioni dei semafori potrebbero permettere di far andare il valore in negativo. Questo serve per misurare il numero dei processi in attesa di quel semaforo. <br> | ||
| + | '''Il problema della cena dei filosofi''': <br> | ||
| + | 5 filosofi passano la loro vita pensando e mangiando. Condividono un tavolo circolare con 5 sedie e ogni sedia appartiene a un solo filosofo. Alla sinistra e alla destra di ogni piatto c'è una bacchetta per un totale di 5 bacchette. La bacchetta destra che un filosofo usa per mangiare viene quindi utilizzata come bacchetta sinistra dal filosofo alla sua destra e simmetricamente è uguale per il filosofo che siede a sinistra. <br> | ||
| + | Ogni tanto un filosofo smette di pensare e cerca di prendere le rispettive bacchette, se ci riesce può mangiare e poi rilasciare le bacchette. <br> | ||
| + | Questo problema è un modello di problema ad accesso a ''insiemi'' di risorse. Mentre nel produttore/consumatore e buffer limitato gli attori in gioco avevano la necessità di avere l'accesso esclusivo a una sola risorsa in questo problema è richiesto l'accesso a insiemi di risorse (le bacchette) le cui parti possono essere desiderate da altri richiedenti. | ||
| + | * soluzione con contesa sulle posate e casi di deadlock | ||
| + | :Poniamo un semaforo per ogni bacchetta. Può succedere però, se nel implementazione i filosofi "prendono in mano" prima la bacchetta destra e poi quella sinistra, che tutti prendono in mano contemporaneamente la bacchetta destra e rimangono in un'attesa infinita della bacchetta sinistra che non gli verrà mai rilasciata perché anche il rispettivo filosofo alla propria sinistra è in attesa. <br> Questo è un caso di deadlock. <br> | ||
| + | :Una soluzione può essere quella di imporre che un filosofo sia "mancino" cioè prenda prima la bacchetta a sinistra e poi la destra. <br> | ||
| + | * soluzione con acquisizione atomica di entrambe le posate, casi di starvation | ||
| + | :Un'altra soluzione è quella di rendere atomico l'acquisizione di entrambe le posate. <br> | ||
| + | :Può succede che 4 filosofi compiano una "congiura", cioè siano d'accordo a non lasciar risorse a un quinto filosofo. Questo è un caso di starvation e non è irreale in quando i 4 filosofi potrebbero essere processi malevoli che siano stati programmati di proposito per questo. | ||
| + | '''System Call''': | ||
| + | * POSIX. | ||
| + | :Il POSIX è uno standard (IEEE 1003) che definisce le signature delle system call. Un sistema operativo deve rispettare il POSIX per essere definito "Unix-like". <br> | ||
| + | :Di solito i parametri delle system call sono pensati per essere contenuti in un registro. Quasi sempre le system call ritornano un intero: 0 se la procedura è stata eseguita correttamente, -1 se c'è un errore. Quando una system call ritorna -1 la variabile "globale" errno (error number) contiene il codice di errore. La variabile errno non è realmente globale perché ne esiste una per ogni processo. <br> | ||
| + | :Unix è un sistema operativo file-system centrico quindi quando facciamo input/output anche da periferiche come stampanti e lettori CD usiamo le system call per la scrittura/lettura dei file. <br> | ||
| + | :Un catalogo delle system call principali può essere trovato [[Il ''catalogo'' delle System Call | qui]]. | ||
| + | * fork/exec | ||
| + | :fork e exec sono system call importanti e servono per creare un nuovo processo: <br> | ||
| + | :fork: genera un processo clone di quello che ha chiamato fork. <br> | ||
| + | :exec: "cambia" il codice eseguito dal processo corrente. <br> | ||
| + | :Quindi per "aprire un nuovo programma" si utilizza una fork seguita da un exec. | ||
| + | |||
== Lezione del 4 novembre 2016 == | == Lezione del 4 novembre 2016 == | ||
| + | Audio Lezione: [https://drive.google.com/open?id=0B8G3NNuJ7MA7blhMT0tSNDRGSUU 4/11/16] | ||
| + | |||
| + | * '''Problema della Cena dei filosofi'''. Soluzione con acquisizione atomica delle bacchette (con starvation) | ||
| + | * '''Tecnica del passaggio del testimone''' (Passing the Baton). | ||
| + | |||
| + | : Non uscire dalla mutua esclusione se c'è qualcun altro che vuole entrarci e semplicemente fare in modo che lui l'acquisisca. La mutua esclusione termina solo se non c'è nessuno che più la richiede. | ||
| + | |||
| + | ESEMPIO IMPLEMENAZIONE BATON | ||
| + | <syntaxhighlight lang=C> | ||
| + | void baton(int i) { | ||
| + | int j; | ||
| + | for (j=1; j<5; j++) { | ||
| + | if(philo_status[(i+j)%5] == 'W' && philo_status[(i+j+1)%5] != 'E' && philo_status[(i+j+4)%5] != 'E') { | ||
| + | semaphore_V(philowait[(i+j)%5]); | ||
| + | return; | ||
| + | } | ||
| + | } | ||
| + | semaphore_V(mutex); | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | * '''Cena dei filosofi, acquisizione atomica delle bacchette con passaggio del testimone'''. | ||
| + | * '''Implementazione della congiura dei filosofi''' | ||
| + | |||
| + | * '''Le system call di gestione file (open, read, write, close, lseek)''' | ||
| + | Quando lavoriamo con dei file dobbiamo sempre specificare se vogliamo solo leggerli oppure anche scrivere, magari in append mode. Ci sono quindi varie modalità con cui possiamo interagire con i file. <br> | ||
| + | Un utente potrebbe essere autorizzato a gestire il file in certe modalità oppure no. <br> | ||
| + | Il descrittore di un file è un intero. <br> | ||
| + | Le system call, a differenza delle chiamate di funzioni di libreria, non sono bufferizzate. | ||
| + | |||
| + | ESEMPIO | ||
| + | |||
| + | Se si decommenta printf stampa 2 volte hello world perchè la stringa resta nel buffer. | ||
| + | |||
| + | Se si decommenta write stampa 1 volta hello world. | ||
| + | |||
| + | Per vedere le chiamate di sistema effettuate in fase di esecuzione, compilare il codice sorgente e poi utilizzare strace -f "eseguibile". | ||
| + | <syntaxhighlight lang=C> | ||
| + | #include<stdio.h> | ||
| + | #include<unistd.h> | ||
| + | |||
| + | int main(int argc, char* argv[]){ | ||
| + | //printf("hello world"); //if you ends the strings with \n is like to "fflushing" the buffer | ||
| + | //write(1, "hello world", 11); // 1 and 11 are file descriptors | ||
| + | switch(fork()) { | ||
| + | case 0: //child | ||
| + | break; | ||
| + | default: //parent | ||
| + | wait(NULL); | ||
| + | break; | ||
| + | case -1: //error | ||
| + | break; | ||
| + | } | ||
| + | printf("\n"); | ||
| + | return 0; | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
| + | Copia il file passato come primo argomento (argv[1]) nel file passato come secondo argomento (argv[2]), se quest'ultimo non esiste, allora lo crea. | ||
| + | <syntaxhighlight lang=C> | ||
| + | #include<stdio.h> | ||
| + | #define BUFSIZE 2048 | ||
| + | char buffer[BUFSIZE]; | ||
| + | int main(int argc, char *argv[]){ | ||
| + | int fdin = open(argv[1], O_RDONLY); | ||
| + | int fdout = open(argv[2], O_WRONLY | O_CREAT | O_TRUNC, 0666); //0666 is the umask used to modify the permissions of new files | ||
| + | |||
| + | int n; | ||
| + | while((n = read(fdin, buffer, BUFSIZE)) > 0) | ||
| + | write(fdout, buffer, n); | ||
| + | |||
| + | close(fdin); | ||
| + | close(fdout); | ||
| + | return 0; | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
| + | '''umask''' <br> | ||
| + | Con la open possiamo usare dei permessi al massimo per quelli garantiti dal umask. <br> | ||
| + | Un numero composto da quattro cifre ottali. Controlla la maschera di creazione dei file. I bit di permesso contenuti nella maschera NON vengono settati nel nuovo file creato. Corrisponde all'opereazione: | ||
| + | |||
| + | R:(D &(~M)) | ||
| + | |||
| + | Può essere vista come una sottrazione, i bit accesi nella umask vengono spenti nel file creato. | ||
| + | |||
| + | e.g. se i permessi di default corrispondono a 0666(D) e la maschera corrisponde a 0022(M), R è uguale a 0666-0022 = 0644. Infatti | ||
| + | |||
| + | 0022 = |000|000|010|010| | ||
| + | ~0022 = |111|111|101|101|(7755) | ||
| + | 0666 = |000|110|110|110| | ||
| + | ~0022 & 0666 = |000|110|100|100|(0644) | ||
| + | |||
| + | Tabella significato cifre umask | ||
| + | |||
| + | OTTALE BINARIO SIGNIFICATO | ||
| + | 0 000 Nessun permesso | ||
| + | 1 001 Solo esecuzione | ||
| + | 2 010 Solo scrittura | ||
| + | 3 011 Scrittura ed esecuzione | ||
| + | 4 100 Solo lettura | ||
| + | 5 101 Lettura ed esecuzione | ||
| + | 6 110 Lettura e scrittura | ||
| + | 7 111 Lettura, scrittura ed esecuzione | ||
| + | |||
| + | I permessi sono rappresentati in simboli come segue: | ||
| + | |||
| + | r: read | ||
| + | w: write | ||
| + | x: execute | ||
| + | |||
| + | '''umask - S''' da shell per visualizzare la umask attuale con rappresentazione simbolica | ||
| + | |||
| + | '''ls -l "nomefile"''' da shell per visualizzare i permessi del file in notazione simbolica: '-' seguito da 3 triple che indicano i permessi di accesso per '''ugo''', ovvero, rispettivamente, per user, per group, per other. | ||
| + | |||
| + | ESEMPIO | ||
| + | -rw-r--r-- | ||
| + | |||
| + | |||
| + | |||
| + | * '''File aperti durante fork/exec'''https://www.kernel.org/ | ||
| + | |||
| + | I file aperti vengono ereditati dai processi figli. | ||
| + | Processo padre e processo figlio condividono lo stesso offset nei file comuni. In questo modo si evita di sovrascriversi a vicenda. Ogni volta che il padre o il figlio scrivono sul file aggiornano l'offset comune.In questo modo se l'altro processo vuole anche lui scrivere in quel file partirà dal offset aggiornato e non sovrascriverà i dati scritti dal altro processo. <br> | ||
| + | |||
| + | * '''La system call dup e la ridirezione''' | ||
| + | E' possibile fare in modo che più file descriptor siano associati a un unico file (per la precisione a un unica file table, che serve per gestire un file). <br> | ||
| + | La system call dup permette di fare ciò. Ritorna un nuovo file descriptor che punta a una file table già esistente.<br> | ||
| + | Possiamo quindi "ridirezionare" l'output o l'input di un processo figlio modificando i file descriptor prima di creare il processo figlio. Per esempio possiamo modificare un file descriptor che puntava a un normale file in modo che punti a un file di standard output e quindi anche se al processo figlio sembrerà di scrivere in un normale file starà scrivendo nel terminale. | ||
| + | |||
| + | ESEMPIO | ||
| + | |||
| + | <syntaxhighlight lang=C> | ||
| + | #include<sys/types.h> | ||
| + | #include<sys/stat.h> | ||
| + | #include<fcntl.h> | ||
| + | #include<stdio.h> | ||
| + | #include<unistd.h> | ||
| + | |||
| + | int main(int argc, char * argv[]){ | ||
| + | int fdout; | ||
| + | if(argc > 1); | ||
| + | fdout = open (argv[1], O_WRONLY | O_CREAT | O_TRUNC, 0666); | ||
| + | switch(fork()) { | ||
| + | case 0: //child | ||
| + | dup2(fdout, 1); // duplica descrittore file, posso ridirezionare l'output. E' come fare '>' dalla shell | ||
| + | execlp(”ls”, “-l”, 0); | ||
| + | close(fdout); | ||
| + | break; | ||
| + | default: // parent | ||
| + | wait(NULL); | ||
| + | break; | ||
| + | case -1: // error | ||
| + | break; | ||
| + | } | ||
| + | printf(“\n”); | ||
| + | return 0; | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
== Lezione del 8 novembre 2016 == | == Lezione del 8 novembre 2016 == | ||
| + | '''Codice per la congiura dei filosofi''' | ||
| + | <syntaxhighlight lang=C> | ||
| + | #include <stdio.h> | ||
| + | #include <stdint.h> | ||
| + | #include <pthread.h> | ||
| + | #include "semaphore.h" | ||
| + | |||
| + | semaphore philowait[5]; | ||
| + | semaphore mutex; | ||
| + | semaphore cospsem; | ||
| + | char philo_status[]="TTTTT"; | ||
| + | |||
| + | void baton(int i){ | ||
| + | int j = 0; | ||
| + | //iterate through remaining philosophers | ||
| + | for(j = 1; j < 5;j++){ | ||
| + | //if there's any waiting philosopher, and no other philosophers(on his left and right side) are eating | ||
| + | if(philo_status[(i+j)%5]=='W' && philo_status[(i+j+1)%5]!= 'E' && philo_status[(i+j+4)%5]!='E'){ | ||
| + | semaphore_V(philowait[(i+j)%5]); | ||
| + | return; | ||
| + | } | ||
| + | } | ||
| + | semaphore_V(mutex); | ||
| + | } | ||
| + | |||
| + | void ok2eat(int i){ | ||
| + | semaphore_P(mutex); | ||
| + | philo_status[i]='W'; | ||
| + | if(philo_status[(i+1)%5] == 'E' || philo_status[(i+4)%5] == 'E'){ | ||
| + | semaphore_V(mutex); | ||
| + | semaphore_P(philowait[i]); //wait for baton | ||
| + | } | ||
| + | philo_status[i] = 'E'; | ||
| + | printf("philo eating: %d |%s|\n",i,philo_status); | ||
| + | baton(i); | ||
| + | } | ||
| + | |||
| + | void ok2think(int i){ | ||
| + | semaphore_P(mutex); | ||
| + | philo_status[i] = 'T'; | ||
| + | printf("philo thinking: %d |%s|\n",i,philo_status); | ||
| + | baton(i); | ||
| + | } | ||
| + | |||
| + | void conspiracy_in(){ | ||
| + | static int first_time = 1; //this variable's value is preserved between calls to this function | ||
| + | semaphore_P(mutex); | ||
| + | if(first_time){ | ||
| + | //first conspirator entering here will act like nothing happened | ||
| + | first_time = 0; | ||
| + | } | ||
| + | else{ | ||
| + | //conspire | ||
| + | semaphore_V(cospsem); | ||
| + | } | ||
| + | semaphore_V(mutex); | ||
| + | } | ||
| + | |||
| + | void conspiracy_out(){ | ||
| + | semaphore_P(cospsem); | ||
| + | } | ||
| + | |||
| + | void *philo(void *arg) { | ||
| + | int i = (uintptr_t)arg; | ||
| + | while (1) { | ||
| + | //thinking/still thinking | ||
| + | usleep(random() % 200000); | ||
| + | ok2eat(i); | ||
| + | //eating | ||
| + | |||
| + | //conspirators need to be synchronized to conspire | ||
| + | if(i==1 || i==3) conspiracy_in(); | ||
| + | usleep(random() % 200000); | ||
| + | if(i==1 || i==3) conspiracy_out(); | ||
| + | ok2think(i); | ||
| + | //thinking again | ||
| + | } | ||
| + | } | ||
| + | |||
| + | int main(int argc, char *argv[]) { | ||
| + | int i; | ||
| + | pthread_t philo_t[5]; | ||
| + | srandom(time(NULL)); | ||
| + | mutex = semaphore_create(1); | ||
| + | cospsem = semaphore_create(0); | ||
| + | for (i=0; i<5; i++) | ||
| + | philowait[i]=semaphore_create(0); | ||
| + | for (i=0; i<5; i++) | ||
| + | pthread_create(&philo_t[i], NULL, philo, (void *)(uintptr_t) i); | ||
| + | for (i=0; i<5; i++) | ||
| + | pthread_join(philo_t[i], NULL); | ||
| + | } | ||
| + | </syntaxhighlight> | ||
| + | |||
| + | * '''Problema dei lettori e scrittori''' | ||
| + | :Spesso quando gestiamo la concorrenza all’accesso a strutture dati separiamo i ruoli di solo lettori con anche quello di scrittori (che per fare ciò possono dover anche leggere). | ||
| + | :Mentre che per i lettori non c’è un limite a quanti contemporaneamente possono avere accesso alle informazioni, gli scrittori devono avere accesso esclusivo alla struttura dati. | ||
| + | :Questo perché incorriamo in una race-condition solo quando modifichiamo la struttura dati. | ||
| + | :Dare precedenza di accesso a una categoria o all’altra porta starvation nella categoria con meno priorità. | ||
| + | :Una soluzione che abbiamo dato è quella di dare esclusività ai ruoli a turno: | ||
| + | :dopo che uno scrittore ha finito di scrivere garantisce l’accesso prima a tutti i lettori in attesa e se non sono presenti agli scrittori in attesa. Per i lettori è il contrario: dopo che l’ultimo lettore ha finito di leggere garantisce l’accesso a uno dei possibili scrittori in attesa e se non ce ne sono ai lettori. | ||
| + | :La soluzione in C al problema lettori e scrittori può essere trovata [[Zibaldone|qui]]. | ||
| + | * '''Semafori Binari(Introduzione)''' | ||
| + | : Un semaforo binario è un semaforo ordinario che rispetta la seguente invariante: '''nP<=nV+Init<=nP+1''', ovvero è un semaforo che può assumere solo valori 0 o 1. | ||
| + | : Si può dimostrare che i semafori ordinari sono espressivi tanto quanto quelli binari(e viceversa) fornendo una implementazione di semafori binari tramite i semafori ordinari e viceversa una implementazione di semafori ordinari tramite semafori binari. (l'invariante dei semafori binari si può anche scrivere '''0 <= nV + Init - nP <= 1''' dove '''nV + Init - nP''' rappresenta proprio il valore del semaforo). | ||
| + | |||
== Lezione del 11 novembre 2016 == | == Lezione del 11 novembre 2016 == | ||
| + | * '''Valore di ritorno di un processo''' | ||
| + | :Un processo ritorna un valore che è un numero intero. <br> | ||
| + | :Questo può essere deciso come valore di ritorno del main, oppure con la funzione ''exit''. | ||
| + | :La system call wait aspetta che lo stato di un processo figlio cambi e quando cambia scrive il nuovo in una variabile. <br> | ||
| + | :Quando un programma termina il suo valore di ritorno viene salvato nel descrittore del processo. Se il padre non esegue la wait il descrittore del processo figlio non verrà mai eliminato e il processo figlio rimarrà uno "zombie". | ||
| + | :Un esempio del uso si queste system call si può trovare [[2016-17_Programmi_C#Print_child_exit_status|qui]]. | ||
| + | * '''Pipe''' | ||
| + | :La system call pipe crea un canale monodirezionale che può essere usato per la comunicazione tra processi. Dimostrazione del uso di pipe si può trovare [[2016-17_Programmi_C#Demonstration_of_the_use_of_pipe_system_call|qui]]. | ||
| + | * '''Lo zoo delle exec''' | ||
| + | <syntaxhighlight lang='C'> | ||
| + | int execl(const char *path, const char *arg, ...); | ||
| + | int execlp(const char *file, const char *arg, ...); | ||
| + | int execle(const char *path, const char *arg, ..., char * const envp[]); | ||
| + | int execv(const char *path, char *const argv[]); | ||
| + | int execvp(const char *file, char *const argv[]); | ||
| + | int execvpe(const char *file, char *const argv[],char *const envp[]); | ||
| + | </syntaxhighlight> | ||
| + | Spiegazione dei postfissi: | ||
| + | * l = elenco dei parametri passato tramite parametri a cardinalità variabile (variadic function) | ||
| + | * v = elenco dei parametri passato come array | ||
| + | * p = bisogna specificare il path completo dell'eseguibile | ||
| + | * e = bisogna specificare anche l'enviroment con cui verrà eseguito il programma. L'enviroment è una serie di variabili globali, tra cui il path. Il path è l'elenco dei percorsi dei programmi più usati. | ||
| + | Tutte queste funzioni alla fine sono solo delle interfacce per execve. | ||
| + | * '''Programmazione ad eventi''' | ||
| + | :E' un paradigma di programmazione dove il flusso del programma è determinato dal avverarsi di eventi. Il programmatore specifica il codice (Handlers) che deve essere eseguito al verificarsi di un certo evento. <br> | ||
| + | :System call che sono utili per far questo sono select,pselect,poll,ppoll,epoll. | ||
| + | |||
== Lezione del 15 novembre 2016 == | == Lezione del 15 novembre 2016 == | ||
| + | * '''Differenza tra select,poll,pselect,ppoll e epoll''' | ||
| + | :La poll a differenza della select richiede un array di strutture pollfd invece che una bitmask. Permette di specificare precisi eventi per cui stare in ascolto. <br> | ||
| + | :Le versioni con prefisso "p" implementano anche la gestione dei segnali. <br> | ||
| + | :L'epoll è linux only. E' moderna (2002) e fornisce un file dove leggere direttamente quali file descriptor sono stati modificati in modo da non dover scorrere tutta la lista. | ||
| + | * '''Dimostrazione della equivalenza di potere espressivo fra semafori e semafori binari.''' | ||
| + | :I semafori implementati per dimostrare l'equivalenza possono essere trovati a [[Esperimenti_con_semafori_e_monitor_in_C | questa pagina]]. | ||
| + | * '''Definizione di Monitor.''' | ||
| + | Un monitor è un costrutto ad alto livello per la sincronizzazione pensato ispirandosi alla programmazione ad oggetti. <br> | ||
| + | E' una classe che incapsula la risorsa condivisa, la rende privata e permette di accedere a questa solo tramite metodi. Questi metodi implementano i meccanismi di sincronizzazione. <br> | ||
| + | Uno solo processo può essere al interno del monitor e avere accesso ai dati protetti da mutua esclusione. <br> | ||
| + | E' presente una coda di attesa per l'accesso al monitor. <br> | ||
| + | Definiamo inoltre delle variabili ''condition''. <br> | ||
| + | Gli unici metodi che possono essere chiamati su una condition sono wait e signal. Ogni condition ha una propria coda di attesa <br> | ||
| + | L'operazione wait sospende il chiamante e lo sposta nella coda di attesa della condition. | ||
| + | L'operazione signal risveglia un processo in attesa. Se non c'è nessun processo in attesa all'interno del monitor la signal fa entrare un eventuale processo in attesa di entrare nel monitor. Il chiamante di signal dopo aver risvegliato l'altro possibile processo deve mettersi in attesa per evitare che ci siano due processi in concorrenza al interno del monitor, ma invece di andare nella coda di attesa della condition viene messo in un ''urgent stack'' che ha più priorità rispetto alla coda esterna dei processi in attesa di entrare nel monitor. <br> | ||
| + | Ricapitolando le strutture dati per un monitor sono una coda esterna per l'accesso al monitor, una coda interna (non accessibile da fuori ma non dentro la mutua esclusione) per ogni variabile condizionale e l'urgent stack. <br> | ||
| + | * '''Implementazione dei Semafori tramite monitor.''' | ||
| + | |||
== Lezione del 18 novembre 2016 == | == Lezione del 18 novembre 2016 == | ||
| + | * '''File speciali a blocchi o a caratteri''' | ||
| + | : In Unix molte cose sono rappresentate come file. Per esempio i device come i terminali e le partizioni del disco sono file. Si chiamano ''file speciali'' ma non sono tanto differenti dai file comuni. Utilizzano anche gli stessi sistemi di protezione all'accesso. Si dividono i due categori: | ||
| + | :* File speciali a blocchi: utilizzati maggiormente dai sistemi di storage tipo hard-disk e CD-ROMs. Se per esempio il blocco è di 1024 bytes allora possiamo scrivere e leggere con tale granularità, cioè non potremo mai scrivere soltato 500 bytes ma dovremo scrivere, appunto a "blocchi". | ||
| + | :* File speciali a caratteri: utilizzati maggiormente per dispositivi di input-output tipo mouse,tastiera,terminali ecc.. permettono di lavorare con una granularità di 1 byte ma hanno un accesso sequenziale invece che diretto come i file a blocchi. | ||
| + | :Inoltre nei file speciali l'ampiezza è sostituita da 2 numeri, uno che indica il driver del dispositivo e l'altro le possibili parti del dispositivo, per esempio le partizioni. | ||
| + | * '''System call ioctl''' | ||
| + | : Ioctl serve per controllare dei device. Per esempio permette di fermare la testina di lettura del disco oppure far partire il motore del lettore CD. E' necessaria in quando si è voluto uniformare la lettura e scrittura di stream per tutti i device tramite le system call read/write ma chiaramente ogni dispositivo ha anche le sue diverse necessità e queste vengono soddisfatte da ioctl. | ||
| + | * '''Syscall''' | ||
| + | : Syscall è una funzione di libreria C che serve a chiamare system calls che non hanno una loro interfaccia per il linguaggi C. Per esempio getdents. | ||
| + | * '''System call e funzioni di libreria per directory''' | ||
| + | :Le directories sono sempre file ma si può fare l'accesso solo in lettura, per esempio per ottenere la lista di tutti i file e directory all'interno di quella directory. <br> | ||
| + | :getdents legge un file directory ed è la system call principale, tutte le funzioni di libreria C tipo opendir,readdir,readdir_r(per multithread) chiamano getdents. <br> | ||
| + | :Tutte queste funzioni lavorano con una struct dirent che rappresenta una directory entry. <br> | ||
| + | :Si può usare anche scandir che è reetrant (nessun problema di race condition) e invece di leggere un elemento della directory per volta ritorna direttamente un array di tutti gli element allocato dinamicamente (occorre ricordarsi di deallocare con free tutti gli elementi e l'array stesso). | ||
| + | |||
== Lezione del 22 novembre 2016 == | == Lezione del 22 novembre 2016 == | ||
| + | |||
| + | Problema dei filosofi a cena risolto con i monitor. Soluzione con le condizioni associate alle "bacchette" e con le condizioni associate ai filosofi. | ||
| + | discussione dei problemi di deadlock e starvation nell'implementazione tramite monitor. | ||
| + | |||
| + | Problema dei lettori e scrittori tramite monitor. Soluzione con privilegio ai lettori, agli scrittori e modifiche necessarie per la soluzione priva di starvation. | ||
| + | |||
== Lezione del 25 novembre 2016 == | == Lezione del 25 novembre 2016 == | ||
| + | [[Coding Contest]] | ||
| + | |||
== Lezione del 29 novembre 2016 == | == Lezione del 29 novembre 2016 == | ||
| + | * '''Implementazione dei monitor tramite semafori''' | ||
| + | :Un soluzione simile a quella vista a lezione può essere trovata [[Esperimenti_con_semafori_e_monitor_in_C#Monitor implementati con semafori | qui]]. | ||
| + | * '''Introduzione al message passing''' | ||
| + | :E' un altro modo per fare programmazione concorrente alternativo alla memoria condivisa che abbiamo visto fin ora. | ||
| + | :Se i programmi non condividono memoria ma devono sincronizzarsi per lavorare assieme hanno bisogno di scambiarsi messaggi. | ||
| + | :Per l'indirizzamento serve un sistema di naming, come il pid dei processi. | ||
| + | :Due primitive: send e receive. Nella receive come indirizzo da chi ricevere si può mettere una wildcard in modo da riceve da tutti. | ||
| + | :Nella send invece occorre indicare l'identificativo del destinatario (se si ammettesse di poter inserire una wildcard si spedirebbero messaggi in broadcast/multicast. E' una problematica più complessa che viene trattata nei corsi di sistemi distribuiti). | ||
| + | :Lo scambio di messaggi può essere: | ||
| + | :* Sincrono: send bloccante e receive bloccante, senza memoria di supporto. | ||
| + | :* Asincrono: send non bloccante e receive bloccante, con memoria di supporto. I messaggi spediti rimangono in una coda (di ampiezza massima illimitata nel modello). | ||
| + | :* Completamente asincrono: send non bloccante e receive non bloccante. Poco utilizzato, il destinatario deve fare un polling per controllare se il messaggio è arrivato o no. | ||
| + | :Per dimostrare la stessa espressività dei metodi dobbiamo sempre creare delle librerie e non dobbiamo aggiungere nessun processo. | ||
| + | :La metodologia asincrona è espressiva almeno quanto quella sincrona mentre non è vero il contrario. | ||
| + | :Per creare un metodo sincrono con chiamate asincrone basta bloccare il programma finché non si riceve un acknowledgement. | ||
| + | :Invece per creare un metodo asincrono con chiamate sincrone bisogna aggiungere un processo e quindi questo dimostra che non sono equivalentemente espressive. | ||
| + | * '''Soluzioni di esercizi d'esame''' | ||
| + | ** Problema della lavatrice | ||
| + | ** Problema del ponte a senso unico | ||
| + | |||
== Lezione del 2 dicembre 2016 == | == Lezione del 2 dicembre 2016 == | ||
| + | * '''Implementazione della libreria per message passing''' | ||
| + | :I sorgenti della implementazione possono essere trovati [[Esperimenti con message passing in C|qui]] | ||
| + | * '''I segnali''' | ||
| + | :I segnali sono un metodo di comunicazione tra processi utilizzato in UNIX. | ||
| + | :Ogni segnale è rappresentato da un numero. Per esempio "segmentation fault" è il numero 11. | ||
| + | :La system call kill() serve per inviare un segnale. signal() serve per definire l'handler, una funzione che viene eseguita quando il processo riceve uno specifico segnale. | ||
| + | :Ogni segnale ha il suo handler di default e tramite signal() noi sovrascriviamo il default handler. | ||
| + | * '''Permesso setuid''' | ||
| + | :Permette a dei programmi di eseguire operazioni che hanno bisogno dei permessi di root. L'attributo setUserId attivato vuol dire che il programma verrà eseguito con i privilegi del possessore del file piuttosto di quelli di chi lo esegue. | ||
| + | * '''Proposta di soluzione esercizio 4 del [[Coding Contest 25 novembre 2016]]''' | ||
| + | |||
== Lezione del 6 dicembre 2016 == | == Lezione del 6 dicembre 2016 == | ||
| + | |||
| + | * Implementazione di un servizio di Message Passing Asincrono dato uno sincrono (con processo server). | ||
| + | * Implementazione di un servizio di Message Passing completamente asincrono dato uno sincrono. | ||
| + | * Analisi del potere espressivo dei servizi di message passing. | ||
| + | |||
| + | * kernel monolitici e microkernel | ||
| + | * macchine virtuali a livello di processo e a livello di sistema | ||
| + | |||
| + | I sorgenti degli esperimenti con il message passing sono in [http://www.cs.unibo.it/~renzo/so/tools/mp.extra.tgz questo file]. | ||
| + | |||
== Lezione del 9 dicembre 2016 == | == Lezione del 9 dicembre 2016 == | ||
| + | |||
| + | * Il problema della Cena dei filosofi con il message passing (asincrono) | ||
| + | |||
| + | * Buffer Limitato con message passing (asincrono). | ||
| + | |||
== Lezione del 13 dicembre 2016 == | == Lezione del 13 dicembre 2016 == | ||
| + | |||
| + | La lezione TACE per malattia (influenza) del docente. | ||
| + | |||
== Lezione del 16 dicembre 2016 == | == Lezione del 16 dicembre 2016 == | ||
| + | *'''Specifiche del progetto fase uno''' | ||
| + | Il documento delle specifiche può essere trovato [http://www.cs.unibo.it/~renzo/so/mikaboo/phase1.pdf qui]. | ||
| + | :*List.h | ||
| + | :*Lista dei processi | ||
| + | :*Coda dei thread | ||
| + | :*Code dei messaggi | ||
| + | *'''Autotools''' | ||
| + | :Insieme di strumenti per la generazione automatica di Makefiles. <br> | ||
| + | :comando ''autoreconf'' per generale il file ''configure'' <br> | ||
| + | :''./configure'' per generare makefile. | ||
| + | |||
| + | == Lezione del 21 febbraio 2017 == | ||
| + | '''Argomenti trattati:''' | ||
| + | * '''Visione a strati di un elaboratore''' | ||
| + | :Gli strati sono livelli di astrazione. Ogni strato deve "parlare" il linguaggio del livello sottostante e deve fornire un proprio linguaggio ai livelli superiori. | ||
| + | :Per esempio il sistema operativo parla l'ISA del livello hardware e fornisce alle applicazioni le system call. Il sistema operativo maschera il livello hardware in quanto fornisce la possibilità alle applicazioni di utilizzare istruzioni ISA ma non tutte, per ragioni di sicurezza. | ||
| + | * '''Componenti fondamentali di un sistema operativo''' | ||
| + | :A sua volta il sistema operativo può essere visto come un insieme di strati. Esistono sistemi operativi a singolo strato (come MS-DOS) e più strati (layered). | ||
| + | :Le parti principali in cui possiamo suddividere un sistema operativo sono: | ||
| + | :*<u>Lo scheduler</u> | ||
| + | :*<u>Il memory manager</u> | ||
| + | :*<u>Il file system</u> | ||
| + | :*<u>L'I/O manager</u> | ||
| + | :*<u>Il networking manager</u> | ||
| + | :Di questa lista, gli elementi assolutamente fondamentali per considera un programma un sistema operativo sono lo scheduler e una parte essenziale del memory e I/O manager. | ||
| + | :Il networking e file manager si appoggiano al I/O manager per svolgere i loro compiti. | ||
| + | *'''Bootstrap''' | ||
| + | :Letteralmente "mettersi in piedi tirandosi dai lacci degli stivali", nel senso di attivarsi senza aiuto esterno. All'accensione il computer legge da una ROM le prime istruzioni necessarie. Viene sempre letto dai primi settori della memoria di massa il bootloader. :Il bootloader (per esempio GRUB) conosce già molti filesystem, ma non abbastanza. Il bootloader carica un file system temporaneo apposito chiamato initrd per caricare i moduli necessari al kernel. | ||
| + | *'''Come rappresentiamo i processi''' | ||
| + | :Dobbiamo sia tener conto a che punto siamo arrivati nell'esecuzione del processo sia tener conto delle risorse di cui il processo è detentore. | ||
| + | :Utilizziamo la struttura ''Process Control Block'' (task_struct in linux) per i processi e "Thread Control Block" (task_struct in linux) per i thread. | ||
| + | :Process control block: | ||
| + | :*PID (Process ID) | ||
| + | :*PPID (Parent Process ID) per poter creare una gerarchia di processi | ||
| + | :*punti di accesso alla memoria (codice,dati,tabella di rilocazione,paginazione) | ||
| + | :*lista dei thread | ||
| + | :*owner (se il sistema è multiuser) | ||
| + | :*Risorse del processo | ||
| + | :*Coda dei messaggi per IPC (Inter-Process Communication) | ||
| + | :*accounting (tempo di esecuzione sia in modalità kernel sia in modalità user) | ||
| + | :*valore di ritorno del processo | ||
| + | :Thread control block: | ||
| + | :*TID (Thread ID) | ||
| + | :*stato del processore | ||
| + | :*call stack | ||
| + | :*ready/running/waiting | ||
| + | *'''Avvicendamento dei processi''' | ||
| + | :Definizione di avvicendamento: ''Successione prevista o regolata nel tempo, alternanza.'' | ||
| + | :I context switch avvengono a seguito di trap/interrupt. | ||
| + | :Il ciclo di vita di un processo passa tra gli stati ''ready, running, waiting'' e infine ''term''. | ||
| + | :Lo scheduling (processo decisionale) può venire applicato nelle seguenti 4 situazioni: | ||
| + | :# Quando un processo passa dallo stato di running a quello di waiting | ||
| + | :# Quando un processo passa dallo stato di running a quello di ready | ||
| + | :# Quando un processo passa dallo stato di waiting a quello di ready | ||
| + | :# Quando un processo passa dallo stato di running a quello di term | ||
| + | :Se lo scheduling avviene solo nella situazione 1 e 4 allora si utilizza un metodo non preemptive. Dal momento che la CPU è allocata a un processo questo la detiene finchè non termina o entra di sua spontanea volontà in stato di waiting. La CPU non può decidere di far aspettare un processo spostandolo temporaneamente nella coda dei processi ready. Questo sistema era utilizzato da vecchi sistemi operativi come Windows 3.x e dalle versione di Mac OS prima della versione X. | ||
| + | :Nel preemptive scheduling invece la CPU può decidere di sospendere un processo, questo può creare race condition ma anche un sistema più equo di distribuzione delle risorse. Le race condition vengono risolte con i metodi che abbiamo visto nel primo semestre. | ||
| + | ' | ||
| + | |||
| + | == Lezione del 23 febbraio 2017 == | ||
| + | |||
| + | '''System call''' | ||
| + | |||
| + | Abbiamo analizzato le system call che erano già presenti nella [http://man.cat-v.org/unix-6th/2/ versione 6 di Unix] (1975). <br> | ||
| + | Le abbiamo poi confrontate con quelle attuali del [[Il_%27%27catalogo%27%27_delle_System_Call]]. | ||
| + | |||
| + | '''Shell Scripting''' | ||
| + | |||
| + | Gli script vengono utilizzati per lanciare un demone, guardare i processi, etc. | ||
| + | Anche l'amministrazione di sistema avviene tramite scripting. Ad esempio, dopo il boot, il processo init avvia le funzionalità di sistema tramite script. | ||
| + | |||
| + | Unix unifica l'idea di script con quella di shell. | ||
| + | La shell è un processo che interagisce con l'utente. In Unix la novità introdotta è rappresentata dalla presenza di un linguaggio che riguarda i comandi, utile per scrivere gli script per la shell. | ||
| + | |||
| + | Come indichiamo quale shell usare? Scrivendo nella prima riga #! seguito dal path e dal nome della shell. Il kernel prende ciò che è scritto nella prima riga e lo esegue per interpretare lo script. | ||
| + | Nell'esempio sottostante Script è un commento perchè è preceduto da #. | ||
| + | |||
| + | ESEMPIO | ||
| + | |||
| + | #!/bin/bash | ||
| + | #Script | ||
| + | |||
| + | echo "Hello World!" | ||
| + | |||
| + | Per scrivere script abbiamo bisogno di variabili. Nelle shell queste possono essere di 2 tipi: | ||
| + | |||
| + | - Locali: viste solo dalla shell, non perturbano comportamento dei processi. | ||
| + | |||
| + | - D'ambiente: recepita dai comandi come ambiente. | ||
| + | |||
| + | '''ASSEGNAMENTO E VARIABILI''' | ||
| + | |||
| + | ESEMPIO 1 | ||
| + | |||
| + | a=2 /* Non devono esserci spazi!!! a = 2 doesn't work */ | ||
| + | echo $a /* Stampa 2 */ | ||
| + | echo ${a}a /* Stampa 2a */ | ||
| + | |||
| + | ESEMPIO 2 - Nuova shell | ||
| + | |||
| + | bash /* Apro nuova shell */ | ||
| + | echo $a /* Stamperà una riga vuota perchè la var. a non è locale della nuova shell */ | ||
| + | exit /* chiudo nuova shell */ | ||
| + | |||
| + | ESEMPIO 3 - Esportare variabile locale | ||
| + | |||
| + | export a /* La var. a diventa variabile d'ambiente */ | ||
| + | bash | ||
| + | echo $a /* Ora possiamo chiamare la var. a perchè è diventata d'ambiente */ | ||
| + | |||
| + | ESEMPIO 4 - csh | ||
| + | |||
| + | csh in molti casi dovrebbe già essere installato di default. | ||
| + | Se non è così è possibile installarlo eseguendo | ||
| + | |||
| + | sudo apt-get install csh | ||
| + | |||
| + | csh /* Apro cshell, noterete il simbolo di percentuale % a inizio riga di comando */ | ||
| + | set a=42 /* assegnamento */ | ||
| + | csh /* apro nuova shell */ | ||
| + | echo $a /* non possiamo chiamare a(42) perchè locale alla prima shell, viene chiamata a d'ambiente se presente */ | ||
| + | exit | ||
| + | setenv a 42 /* Per creare una variabile d'ambiente, da notare la mancanza di = */ | ||
| + | csh | ||
| + | echo $a | ||
| + | |||
| + | '''ARGOMENTI''' | ||
| + | |||
| + | Negli script possiamo avere degli argomenti. | ||
| + | Vengono visti come $1, ..., $9, ${10}, etc. | ||
| + | $* indica tutti gli argomenti | ||
| + | |||
| + | ESEMPIO 1 | ||
| + | #!/bin/bash | ||
| + | echo $* /* Richiama tutti gli argomenti */ | ||
| + | echo $1 $2 /* Richiama solo i primi due argomenti */ | ||
| + | shift /* Sposta la riga di comando degli argomenti di una posizione verso sx */ | ||
| + | echo $* | ||
| + | |||
| + | Una volta salvato il file con estensione .sh, eseguire da terminale: | ||
| + | chmod +x nomefile.sh | ||
| + | ./nomefile.sh arg1 arg2 ... | ||
| + | |||
| + | Se passiamo come argomenti: uno due tre quattro, | ||
| + | l'output sarà: | ||
| + | uno due tre quattro | ||
| + | uno due | ||
| + | due tre quattro | ||
| + | |||
| + | A volte dobbiamo proteggere dei caratteri. Alcuni di essi possono essere delle wildcard. Ci sono 3 modi per proteggerli: | ||
| + | \* | ||
| + | '*' | ||
| + | "*" | ||
| + | |||
| + | Analizziamone le differenze tramite un esempio. | ||
| + | |||
| + | ESEMPIO 1 | ||
| + | |||
| + | echo \* // OUTPUT: * | ||
| + | echo '*$a' // OUTPUT: *$a | ||
| + | echo "*$a" // OUTPUT: *2 | ||
| + | |||
| + | Nel primo caso l'escape vale solo per *. Nel secondo caso vale per tutta la stringa. Nel terzo caso vale per * e richiama la variabile. | ||
| + | |||
| + | ESEMPIO 2 | ||
| + | echo ab // OUTPUT: ab | ||
| + | echo "ab" //OUTPUT: ab | ||
| + | |||
| + | echo a b //OUTPUT: ab <-- non rileva gli spazi | ||
| + | echo "a b" //OUTPUT: a b | ||
| + | |||
| + | == Lezione del 28 febbraio 2017 == | ||
| + | '''Argomenti trattati''': | ||
| + | * '''Ciclo di vita di un kernel''' | ||
| + | : Dopo l'inizializzazione (Creazione di code, rilevazione di device, ecc..) si crea a "mano" il primo processo. | ||
| + | : L'esecuzione dello scheduler si alterna a quella dei processi. Quando un processo utente viene eseguito il kernel non ha più il controllo del flusso e gli viene restituito solo quando avviene un interrupt/trap. | ||
| + | * '''Parametri di valutazione di un algoritmo di scheduling''' | ||
| + | ** % Utilizzo CPU: Bisogna cercare di tener utilizzata il processore il più possibile riducendo i momenti di inutilizzo (idle). | ||
| + | ** Produttività (Throughput) Numero di processi completati per unità di tempo | ||
| + | ** Tempo totale (turnaround time) Tempo totale impiegato dall'esecuzione del processo al completamente. Tiene conto del tempo speso in attesa oltre al tempo in esecuzione. | ||
| + | ** Tempo di risposta: Tempo prima che un primo output venga generato dal momento in cui il processo viene eseguito. In un sistema interattivo è importante per non dare all'utente l'idea di malfunzionamento. | ||
| + | ** Tempo di attesa. Non aspettando l'I/O ma bensì tempo speso nella ready queue. | ||
| + | * '''Processi CPU Bound e I/O Bound''' | ||
| + | :: I processi si possono dividere in queste due categorie. I processi che utilizzano il processore per tempi più lunghi (per esempio quelli di calcolo scientifico) si chiamano CPU Bound mentre quelli che richiedono spesso interazioni e si fermano ad aspettare l'I/O si chiamano I/O Bound. Algoritmi di scheduling differenti possono favorire o sfavorire una delle due categorie. L'obbiettivo e trovare un algoritmo che sia ottimale per tutti i processi. | ||
| + | * '''Algoritmi di scheduling''' | ||
| + | ** First come first served | ||
| + | :: Lo scheduler implementa una semplice coda dei processi che hanno richiesto l'esecuzione. E' semplice da capire e creare ma il tempo medio di attesa per un processo può essere lungo. Dipende molto dall'ordine in cui vengono avvicendati processi CPU bound e I/O Bound. Un processo CPU bound può creare un ''effetto convoglio'' e far dipendere il tempo di attesa di altri processi che sono I/O bound al suo tempo di esecuzione. Questo algoritmo non è quindi equo. | ||
| + | :* Shortest job first | ||
| + | :: Forse più correttamente nominato algoritmo ''shortest next CPU burst''. Ad ogni processo viene associato il suo tempo di esecuzione e viene scelto dalla ready queue sempre il processo con il tempo più basso. Per determinare il tempo di esecuzione a priori si utilizza una media esponenziale dei tempi di esecuzione dello stesso processo nel passato. [[File:Media_esponenziale.png]] ''t'' sono le misurazioni recenti mentre 'tau' sono la storia più ''remota''. Il parametro alfa determina quanto la media esponenziale sia basata sulla storia recente o su quella passata. | ||
| + | :* Shortest remaining time first | ||
| + | :: SJF può essere preemptive oppure no. Nel caso preemptive prende il nome di ''Shortest remaining time first''. Se un processo A è in esecuzione e arriva un'altro processo B con tempo di esecuzione minore allora A viene fermato e viene eseguito B. La priorità di A nella coda è ora il tempo stimato rimanente. | ||
| + | :* Round robin | ||
| + | :: E' definita un unità di tempo, di solito tra i 10 e i 100 millisecondi, e ogni processo ha un tempo massimo di esecuzione pari a questa unità. I processi vengono avvicendati a turno in una coda. Un processo termina l'esecuzione o per sua volontà (il tempo rimasto del quanto di tempo non è considerato) oppure perchè è scattato l'interval timer. Nell'ultimo caso il processo viene inserito in coda come se fosse un processo appena arrivato. La performance di questo algoritmo dipendono molto da che tipi di processi si gestiscono e dalla dimensione dell'unita di tempo. Se questa è larga allora l'algoritmo è più simile a FCFS mentre un'unita di tempo piccola porta a più context switch e quindi a più overhead. L'unità di tempo andrebbe decisa in proporzione al tempo di context switch. | ||
| + | :* Scheduling a priorità | ||
| + | :: Ad ogni processo è assegnata una priorità che si riflette nella priorità che ha il processo nella ready queue. | ||
| + | :: La priorità di un processo può essere influenzata da fattori interni (come i requisiti di memoria) o esterni al sistema operativo (come ''l'importanza'' di un processo). L'algoritmo può essere non preemptive o premtive, nel caso in cui interrompa il processo attuale se arriva un processo con più priorità. | ||
| + | :: L'SJF può essere visto come un caso particolare di scheduling a priorità, in cui la priorità e appunto inversamente proporzionale al tempo di esecuzione. | ||
| + | :: Un problema dello scheduling a priorità è la starvation, che può essere risolta con il meccanismo di ''aging'' in cui un processo aumenta di priorità proporzionalmente al tempo cui rimane nella ready queue. | ||
| + | :* Scheduler multilivello | ||
| + | :: Questo è lo scheduler più completo in quanto divide i processi in gruppi e utilizza differenti algoritmi per ogni gruppo. | ||
| + | :: Una tipica suddivisione è quella di processi foreground e background, rispettivamente I/O bound e CPU bound. Per ogni gruppo viene creata una coda apposita. | ||
| + | |||
| + | == Lezione del 2 marzo 2017 == | ||
| + | |||
| + | '''Shell Scripting''' | ||
| + | |||
| + | '$' seguito da caratteri esegue una sostituzione, questa può essere: | ||
| + | |||
| + | '''ESEMPIO 1 (contenuto)''' | ||
| + | |||
| + | echo $SHELL | ||
| + | |||
| + | echo $USER | ||
| + | |||
| + | '''ESEMPIO 2 (comando)''' | ||
| + | |||
| + | echo $ls | ||
| + | |||
| + | '''ESEMPIO 2.1''' | ||
| + | |||
| + | du -s $(ls -d *es) //du -s prende come input l'output del comando compreso tra parentesi tonde | ||
| + | |||
| + | '''ESEMPIO 3 (wildcard)''' | ||
| + | |||
| + | echo * // tutti file/dir | ||
| + | echo *es // file/dir che terminanon con es | ||
| + | echo *[lg]es // file/dir che terminanon con les/ges | ||
| + | echo ????? // file/dir con 5 caratteri | ||
| + | |||
| + | Queste wildcard servono per poter individuare insiemi di file in un colpo solo. | ||
| + | |||
| + | '''ESEMPIO 4 ($ come sintassi riconosciuta da grep)''' | ||
| + | |||
| + | grep '>$' *.c // trova tutte le linee che terminano con '>' all'interno dei file .c | ||
| + | |||
| + | '''ESEMPIO 5 (PID)''' | ||
| + | |||
| + | echo $$ // restituisce PID dello script nel quale viene eseguito | ||
| + | |||
| + | '''ESEMPIO 6a''' | ||
| + | |||
| + | echo $1 $2 $3 >/tmp/tmpscript //scrive i 3 argomenti in tmpscript | ||
| + | |||
| + | cat /tmp/tmpscript //lettura tmpscript | ||
| + | rm -f /tmp/tmpscript //rimozione tmpscript | ||
| + | |||
| + | Se cerchiamo di lanciare quasi contemporaneamente lo script dell'esempio 6 in due shell differenti, lo script non funziona perchè lavorano sullo stesso file. Possiamo quindi ricorrere all'utilizzo di $$. | ||
| + | |||
| + | '''ESEMPIO 6b''' | ||
| + | |||
| + | echo $1 $2 $3 >/tmp/tmpscript$$ | ||
| + | |||
| + | sleep 3 //in modo da poter lanciare lo script in un'altra shell | ||
| + | cat /tmp/tmpscript$$ | ||
| + | rm -f /tmp/tmpscript$$ | ||
| + | |||
| + | '''ESEMPIO 7''' | ||
| + | grep bash myscript.sh >& dev/null //ridireziono l'output di grep sul "null device" | ||
| + | echo $? //restituisce 0 se il comando precedente è stato eseguito correttamente, 1 altrimenti | ||
| + | |||
| + | '''Gli operatori >> e <<''' | ||
| + | |||
| + | >> è simile a > ma scrive alla fine del file invece che all'inizio. <br> | ||
| + | << serve invece per inserire l'input di un comando direttamente nello script, come mostrato nel successivo esempio della mail. | ||
| + | |||
| + | '''ESEMPIO 8 (script per inviare mail)''' | ||
| + | |||
| + | #!/bin/bash | ||
| + | |||
| + | mail $1 << ENDOFMESSAGE | ||
| + | ciao $1 questa è una mail di prova | ||
| + | ENDOFMESSAGE //etichetta usata per indicare il termine del messaggio | ||
| + | |||
| + | Con | ||
| + | |||
| + | echo $1; echo $2; ls | ||
| + | |||
| + | raggruppiamo una sequenza di comandi sulla stessa riga | ||
| + | |||
| + | |||
| + | '''ESEMPIO 9((|| &&)''' | ||
| + | |||
| + | Gli operatori || e && possono essere utilizzati per processare più comandi consecutivamente. | ||
| + | |||
| + | command || die | ||
| + | |||
| + | gcc -o hwx hw.c && ./hwx | ||
| + | |||
| + | '''ESEMPIO 10 (sottoshell)''' | ||
| + | |||
| + | Una lista di comandi all'interno di () viene eseguita in una sottoshell. Le variabili all'interno della sottoshell non sono visibili al di fuori del blocco di codice nella sottoshell. Sono variabili locali. | ||
| + | |||
| + | (cd subdir; ls) //eseguo un comando in un'altra directory | ||
| + | |||
| + | '''Pushd e popd''' | ||
| + | |||
| + | Simili al comando ''cd'' ma pushd inserisce i percorsi visitati in una pila e tramite popd e possibile ripercorrere a ritroso le directory visitate. | ||
| + | |||
| + | '''ESEMPIO 11 (background jobs) | ||
| + | ping google.com & //esegue ping in background | ||
| + | jobs //mostra la lista dei jobs in esecuzione | ||
| + | //poniamo che l'output di jobs sia "[1]+ In esecuzione ping google.com &" | ||
| + | kill -9 %1 //termina il processo con identificatore 1 | ||
| + | ''bg'' repristina un processo fermato con CTRL+Z. <br> | ||
| + | ''fg'' riporta in primo piano un processo mandato in background. | ||
| + | |||
| + | '''test e type''' | ||
| + | |||
| + | ''test'' serve a comparare valori e controllare il tipo dei file. <br> | ||
| + | la sintassi ''[]'' è un alias di test. | ||
| + | if [ $$ -eq '10853' ] ; then echo "il processo corrente ha pid 10853"; else echo "il processo corrente non ha pid 10853"; fi; | ||
| + | //che è equivalente a | ||
| + | if test $$ -eq '10853'; then echo "il processo corrente ha pid 10853"; else echo "il processo corrente non ha pid 10853"; fi; | ||
| + | ''type'' invece mostra l'origine di un comando, se sono integrati nella shell oppure è un programma a parte. | ||
| + | |||
| + | '''Switch''' | ||
| + | Sintassi degli switch in bash. | ||
| + | case expression in | ||
| + | pattern1 ) | ||
| + | statements ;; | ||
| + | pattern2 ) | ||
| + | statements ;; | ||
| + | ... | ||
| + | esac | ||
| + | '''Comando cron''' <br> | ||
| + | ''cron'' serve per eseguire operazioni pianificate. Gli script in /etc/init.d vengono eseguiti automaticamente da cron. | ||
| + | |||
| + | '''xarg''' <br> | ||
| + | xarg permette di eseguire un comando passandogli come parametri i valori letti da standard input. | ||
| + | |||
| + | '''uniq''' <br> | ||
| + | uniq può essere usato per trovare e eliminare righe duplicate. | ||
| + | |||
| + | '''wc''' <br> | ||
| + | ''wc'' crea il ''word count'' di un file. Non conta solo le parole ma anche i caratteri e le righe. | ||
| + | |||
| + | '''diff e patch''' <br> | ||
| + | Il comando ''diff'' può essere utilizzato per mostrare le differenze tra due file testuali. E' utilizzato internamente da git. <br> | ||
| + | Patch serve per applicare un ''diff file'' a un altro file in modo da aggiornarlo. | ||
| + | |||
| + | == Lezione del 7 marzo 2017 == | ||
| + | Una risorsa è ogni elemento utile all'elaborazione. | ||
| + | * '''Classificazione di risorse''' | ||
| + | ** '''Fisiche e logiche''' | ||
| + | ::Esempi: | ||
| + | ::CPU, memoria e dispositivi sono risorse ''fisiche''. | ||
| + | ::file, strutture dati, critical section sono risorse ''logiche''. | ||
| + | :* '''Fungibili''' | ||
| + | ::Una risorsa è fungibile se è uguale prendere un bene o un'altro se sono dello stesso tipo. Richiedere un area di memoria o un altra è indifferente se tutte e due soddisfano i requisiti del processo. Richiedere file o dispositivi differenti invece cambia. | ||
| + | :* '''Assegnazione statica o dinamica''' | ||
| + | ::L'assegnazione statica prevede che una risorsa sia monopolio di un processo. | ||
| + | :* '''Accetta richieste multiple o solo singole''' | ||
| + | :: Se può ricevere richieste d'uso da più processi e memorizzare/servire contemporaneamente le richieste oppure no. | ||
| + | :* '''condivisibili e non condivisibili''' | ||
| + | :: Un file in lettura è una risorsa condivisibile, più processi possono accedere contemporaneamente. Un file in scrittura invece è una risorsa non condivisibile perché potrebbe capitare una race condition. | ||
| + | :* '''bloccante e non bloccante''' | ||
| + | ::Se l'accesso alla risorsa implica dei tempi di attesa relativamente lunghi al processo, la risorsa è da considerarsi bloccante. | ||
| + | :* '''prelasciabile o non prelasciabile''' | ||
| + | ::Il processo può rilasciare in qualsiasi momento la risorsa e permetterne l'uso ad un altro processo? Una stampante è un esempio di risorsa non prerilasciabile. | ||
| + | * '''Deadlock''' | ||
| + | :Un deadlock può avvenire in presenza di risorse bloccanti, non condivisibili, non prerilasciabili e con una situazione di attesa circolare. | ||
| + | :* '''detection: grafo di Holt ''' | ||
| + | ::I grafi di allocazione delle risorse, introdotti da Holt nel 1972 sono un buon modo per descrivere lo stato di un sistema e prevedere possibili deadlock. Ogni nodo rappresenta una risorsa o un processo. Di solito le risorse sono rappresentate da quadrati e i processi da cerchi. Un arco da un processo a una risorsa significa che quel processo ha richiesto un'istanza della risorsa. Un arco da una risorsa a un processo vuol dire che un'istanza di quella risorsa è stata assegnata al processo. <br> | ||
| + | ::* ''' teorema dei cicli in grafi di Holt con un solo tipo di risorsa | ||
| + | :::Se il grafo non contiene cicli allora di sicuro non possono esserci deadlock. | ||
| + | :::Se il grafo contiene un ciclo allora <u>può</u> esserci un deadlock. | ||
| + | :::Se le risorse coinvolte in un ciclo hanno solo un'istanza o ogni loro istanza e coinvolta in un ciclo allora c'è di sicuro un deadlock. | ||
| + | :::Questo tecnica di permette di analizzare uno stato ''attuale'' di un sistema, ma dobbiamo trovare un modo per prevedere lo stato ''futuro'' del sistema e quindi prevedere i deadlock. | ||
| + | ::* '''processo di riduzione | ||
| + | :::Per vedere lo stato di un sistema futuro possiamo usare un processo di riduzione del grafo di allocazione delle risorse. | ||
| + | :::Se una risorsa allocata a un processo può essere data dopo un certo periodo a un altro processo che l'ha richiesta allora si può fare una riduzione. Una riduzione consiste nell'eliminare un arco risorsa-processo perchè quel processo ha finito di utilizzare la risorsa oppure è stata prerilasciata e invertire un arco processo-risorsa di un processo che aveva richiesto la risorsa in un arco risorsa-processo. | ||
| + | :::Se un grafo può essere ridotto per tutti i suoi processi allora non può esserci deadlock. | ||
| + | :::Il problema di questo metodo/algoritmo è che nel momento che deallochiamo una risorsa a un processo e più processi avevano richiesto quella risorsa come scegliamo deterministicamente a quale processo assegnare la risorsa? Dovremmo provare tutti i casi per accertarsi che non si crei deadlock, ciò significa fare backtrack e perdere la polinomialità dell'algoritmo. | ||
| + | ::* '''definizione di Knot | ||
| + | :::Il Knot è una caratteristica di un grafo che si verifica velocemente e permette di determinare possibili deadlock. | ||
| + | :::Un knot è un insieme di nodi in cui, per ogni nodo del knot, tutti e solo i nodi del knot sono raggiungibili da quel nodo. | ||
| + | :::Un knot è una condizione sufficiente ma non necessaria per i deadlock. Ciò vuol dire che possono capitare deadlock anche senza la presenta di un knot. | ||
| + | ::* '''teorema dei knot nei grafi di Holt con più tipi di risorse | ||
| + | :::Dato un grafo di Holt con una sola richiesta sospesa per processo. | ||
| + | :::Il grafo rappresenta uno stato di deadlock solo se esiste un knot. | ||
| + | :* '''prevention''' | ||
| + | ::Se il sistema cerca di non far verificare almeno una delle condizioni necessarie al deadlock allora questo non si verificherà mai. | ||
| + | ::Questo però comporta anche sottoutilizzo delle risorse del sistema. | ||
| + | :* '''avoidance''' | ||
| + | ::*'''Condizione di safety''' | ||
| + | :::Un sistema è in una condizione di safety se esiste una safe sequence. | ||
| + | :::Una safe sequence è una sequenza di processi dove per ogni richiesta di risorse di un processo questa richiesta può essere soddisfatta con le richieste disponibili al momento più tutte le risorse allocate precedentemente ai precedenti processi della sequenza. | ||
| + | :::Finchè c'è safety non possono verificarsi deadlock. In una situazione unsafe non è detto che capiti deadlock, ma è possibile. | ||
| + | ::*'''algoritmo del Banchiere (mono e multivaluta). | ||
| + | :::L'algoritmo del banchiere si basa sul fatto che una banca non dovrebbe mai rimanere senza denaro da prestare ai clienti. | ||
| + | :::Vengono mantenute varie strutture dati come il capitale iniziale della banca, quanto è disponibile in cassa, quanto è stato prestato ad ogni cliente e quanto si può ancora prestare ad ogni cliente (in base al ''credito'' che ogni cliente ha). | ||
| + | :::La condizione di safety è data dalla condizione che bisogna mantenere almeno uno dei clienti soddisfacibile cioè che il denaro in cassa sia maggiore del possibile richiesta di prestito di almeno un cliente. | ||
| + | :::Se questa condizione non si verificasse alloca il banchiere deve aspettare che un cliente restituisca il prestito. | ||
| + | :::In caso di più valute (yen, dollari, euro, ...) che rappresentano i tipi diversi di risorse del sistema. Tutte le strutture dati aumentano di una dimensione, per esempio il denaro iniziale diventa un vettore. | ||
| + | ::Teorema: il processo di controllo di safety non ha necessita' di backtrack. | ||
| + | :* '''Tecnica dell'ostrica/struzzo''' | ||
| + | ::Un altro modo per gestire i deadlock e quello di ignorarli completamente. | ||
| + | ::La maggior parte dei sistemi operativi utilizza questo metodo. | ||
| + | ::Soprattuto in sistemi in cui è statisticamente determinato che i deadlock si verificano poco frequentemente i sistemi di prevenzione e avoidance costituirebbero un overhead troppo elevato. | ||
| + | ::Sta allora alle singole applicazioni evitare di crearli. | ||
| + | |||
| + | == Lezione del 9 marzo 2017 == | ||
| + | |||
| + | * awk | ||
| + | * phase2: prime fasi del boot | ||
| + | * python: presentazione del linguaggio ed analisi delle caratteristiche | ||
| + | |||
| + | == Lezione del 14 marzo 2017 == | ||
| + | '''Gestione della memoria''' | ||
| + | * Binding a tempo di esecuzione, compilazione o esecuzione | ||
| + | * Memory Management Unit (MMU) | ||
| + | * Allocazione statica o dinamica | ||
| + | * Allocazione continua o non contigua | ||
| + | * Metodo delle partizioni fisse | ||
| + | : Problema della frammentazione interna. | ||
| + | * Metodo delle partizioni variabili | ||
| + | :Problema della frammentazione esterna. | ||
| + | :* Algoritmi di scelta dell'area di allocazione | ||
| + | :** First fit | ||
| + | :** Best fit | ||
| + | :** Worst fit | ||
| + | :** Next fit | ||
| + | :* Paginazione | ||
| + | :* Segmentazione | ||
| + | :* Memoria virtuale | ||
| + | |||
| + | == Lezione del 16 marzo 2017 == | ||
| + | * '''Progetto phase2''': analisi del manuale di uARM | ||
| + | * '''Python''': funzioni, oop, @memoize, @trace | ||
| + | |||
| + | == Lezione del 21 marzo 2017 == | ||
| + | |||
| + | La lezione del 21 marzo tace per impegno del docente. | ||
| + | |||
| + | == Lezione del 23 marzo 2017 == | ||
| + | '''Memoria virtuale''': <br> | ||
| + | '''Algoritmi di paginazione:''' | ||
| + | Quando avviene un page fault serve un algoritmo per trovare la pagina "meno utile" in memoria a cui sostituire la pagina richiesta. | ||
| + | * '''FIFO''' viene sostituita la pagina che da più tempo è in memoria | ||
| + | * '''LFU''' ''Least Frequently Used'' contando il numero di richieste alla pagina possiamo calcolare quali sono le pagine più richieste e tenere solo quelle in memoria. Il problema è che una pagina potrebbe essere richiesta molto in una fase iniziale di un processo, quindi avere un rank elevato, però poi non essere più utilizzata. Una soluzione a questo problema è quella di shiftare a destra di 1 i bit del contatore degli utilizzi a intervalli regolari, ponendo questo in un decadimento esponenziale. | ||
| + | * '''LRU''' ''Least Recently Used'' si sostituisce la pagina che non è stata utilizzata da più tempo. | ||
| + | * '''Algoritmo ottimo''' algoritmo teorico utile per fare ''benchmark'' degli altri algoritmi. Se conosciamo a priori la ''reference string'' una sequenza che indica quali saranno le richieste delle pagine nel futuro, possiamo sostituire le pagine che per più tempo non saranno richieste, riducendo al minimo i page fault. | ||
| + | '''Anomalia di Belady''' | ||
| + | Abbiamo dimostrato che l'algoritmo FIFO all'aumentare della memoria può peggiorare di performance. | ||
| + | |||
| + | == Lezione del 28 marzo 2017 == | ||
| + | '''Algoritmo second chance o dell'orologio''' <br> | ||
| + | '''Linking statico'''<br> | ||
| + | '''Loading dinamico'''<br> | ||
| + | '''Memoria secondaria'''<br> | ||
| + | '''Algoritmi di scheduling delle seek'''<br> | ||
| + | *'''FIFO''' | ||
| + | *'''SSF''' | ||
| + | *'''c-look''' | ||
| + | |||
| + | == Lezione del 30 marzo 2017 == | ||
| + | '''Discussione sulle specifiche del progetto'''<br> | ||
| + | :Creazione pagina [[Specifiche_phase_2_2016/17]] | ||
| + | '''Python standard library''' | ||
| + | * libreria sys: Permette di prendere parametri da linea di comando. Si utilizza ''sys.argv''. | ||
| + | * libreria os: Permette di navigare nella gerarchia di directory con ''os.walk''. | ||
| + | |||
| + | == Lezione del 4 aprile 2017 == | ||
| + | '''RAID''' <br> | ||
| + | (Redundant Array Inexpensive/Independent Disks) | ||
| + | |||
| + | l’idea principale nasce per ottenere maggiori performance (raid 0 ed 1), non maggiore affidabilità (raid 4 e 5). | ||
| + | |||
| + | * RAID0 (Striping): i dischi sono posti in sequenza.Vengono create le stripe, sequenze di bit che sono posti su n dischi sequenzialmente. Lo striping può essere a vari livelli, a livello di bit, di byte, di settore o di blocco. Quello più utilizzato e il livello di blocco. Cioè per scrivere un file che è composto da più blocchi si suddividono i blocchi in più dischi. Attenzione, file piccoli potrebbero sostare su una sola stripe, quindi su un solo disco. | ||
| + | :Il miglioramento di performance si paga in maggiore faultness. dipende dal costo dei dati salvati. | ||
| + | |||
| + | * RAID1 (mirroring): ogni disco ospita la copia dei dati. doppia velocità in lettura (teoricamente). Stessa velocita di scrittura. | ||
| + | : Size = ½ readSpeed = N wSpeed = ½ N FT = 1 | ||
| + | * RAID10 = 1+0 striping su 2 mirror. | ||
| + | |||
| + | * RAID 2-3 (deprecated):Agisce sui singoli blocchi i dati vengono salvati in maniera sincrona con meccanismi di parità (hoffman per correzione di errori nel RAID2, ciclica per RAID3). | ||
| + | |||
| + | * RAID4: usa dischi normali, non agisce su singoli blocchi ma su stripe ampi. | ||
| + | |||
| + | parityMap = S0 XOR S1 XOR S2 XOR S3 (in caso di 4+1 dischi). | ||
| + | |||
| + | |||
| + | nel caso si rompa S4, i dati non avranno problemi. Se si rompesse un qualunque dei primi 4 dischi, basterà effettuare lo XOR degli altri e copiare tali dati su un nuovo HD. | ||
| + | |||
| + | S1 rotto. | ||
| + | new_S1 = S0 XOR S2 XOR S3 XOR P0123 | ||
| + | Sopporta una sola rottura. | ||
| + | |||
| + | Per aggiornare il disco di parità in caso di modifica a S2 (chiamato ora S2’) | ||
| + | |||
| + | P0123 = P0123 XOR S2 XOR S2’. | ||
| + | il primo xor toglie il valore da P0123 di S2, il secondo XOR aggiunge il valore S2’. | ||
| + | in questo modo, aggiorno solo 2 dischi, e uso gli stessi in lettura per ricalcolare la parità. | ||
| + | |||
| + | Le parità ciclano su tutti i dischi. Esistono controller che effettuano RAID5, oppure e’ possibile ottenere le funzionalità raid via sistema operativo. | ||
| + | |||
| + | * RAID5: | ||
| + | :Senza fault | ||
| + | :Size = N-1/N, rspeed=(N-1), wspeed=(N-2), FT=1 | ||
| + | |||
| + | I dischi RAID soffrono alquanto in caso di terremoti. | ||
| + | |||
| + | '''File System:''' <br> | ||
| + | Servizio per dare una interfaccia più comoda e generale per l’accesso alla memoria secondaria. | ||
| + | |||
| + | Nasce come informatizzazione delle pratiche di ufficio. le pratiche sono salvate in folders, fascicoli, poste poi nelle directories. come visualizzo questa struttura per l’utente? E ad i programmatori? come viene implementato? | ||
| + | |||
| + | Nasce l’idea di “aprire” i file. Nell'accedere da un programma ad il file-system (operazione non banale) si preferisce chiamare un’operazione di apertura, e utilizzare un descrittore al file per agire sul file richiesto. | ||
| + | |||
| + | La struttura di file/folder/directories possono inoltre supportare le astrazioni di condivisione e proprieta’. | ||
| + | Tutti i controlli sono effettuati sono in fase di apertura (in modo da migliorare le performance). | ||
| + | |||
| + | Quali attributi caratterizzano un file? | ||
| + | <ul> | ||
| + | <li>Name,</li> | ||
| + | <li>Type,</li> | ||
| + | <li>Location,</li> | ||
| + | <li>Size,</li> | ||
| + | <li>Ownership,</li> | ||
| + | <li>Protection,</li> | ||
| + | <li>Time stamp</li> | ||
| + | </ul> | ||
| + | UNIX opta per una scelta minimalista. Tutti i file sono stringhe di byte. | ||
| + | AFS (Apple) da un tag di tipo e di creator per ogni file | ||
| + | |||
| + | maggiore e’ il numero di tipi di file, maggiore supporto per essi, ma piu’ codice nel kernel. | ||
| + | I suffissi possono indicare ad altri programmi il tipo. | ||
| + | |||
| + | Semantica della coerenza vs Semantica delle sessioni (Andrew File System) | ||
| + | |||
| + | Per quali motivo vengono create le partizioni? | ||
| + | /var andrebbe in una nuova partizione per un fattore di sicurezza. | ||
| + | |||
| + | Cosa c’e’ effettivamente sul disco? Una sequenza di blocchi, il cui primo (boot block) ha spazio per il bootloader e la tabella delle partizioni (MBR), con 4 elementi. 4 record che indicano dove ogni partizione inizia e finisce. Si possono usare partizioni estese, usando le prime 3 e nella quarta tutto il resto. | ||
| + | |||
| + | Ogni partizione ha all'inizio un BootRecord. | ||
| + | L’ultima partizione contiene nel BootRecord le altre partizioni. | ||
| + | GBT consente di avere un numero arbitrario di partizioni. | ||
| + | |||
| + | Raizer FS, | ||
| + | |||
| + | Read only file systems. | ||
| + | |||
| + | Initrd, ISO9660. | ||
| + | |||
| + | Quando si costruisce l’immagine, in realtà si sta creando il file-system ISO9660. | ||
| + | |||
| + | Come gestire invece file che possono cambiare? | ||
| + | Allocazione indicizzata (a lista): creo un (o vari) blocco/i degli indici che punta ad i blocchi dati. | ||
| + | l’accesso diretto cresce come il logaritmo dell’ampiezza. | ||
| + | Allocazione concatenata (ad albero): (in fondo al blocco indico il successivo). Gestisce bene la dinamicità. Non piace perché’ non é per nulla efficiente l’accesso diretto. | ||
| + | |||
| + | Quali allocazioni usano i filesystem reali oggi? | ||
| + | |||
| + | fat: concatenata. I blocchi tengono solo i dati, esiste una file allocation table (vettore) che indica il prossimo blocco. I puntatori sono tutti vicini e quindi ponendo il vettore in cache, abbiamo disponibili diversi puntatori. | ||
| + | |||
| + | BerkleyFastFileSystem (progenitore dei EXT4…) usano allocazione indicizzata. Nasce per garantire performance ad i file piccoli. Nel descrittore del file (iNode) avra’ N (13 attualmente) puntatori. Uno, il numero 10, ad i blocchi, uno (11) indiretto alla tabella, uno (12) come duplice indiretto e il 13esimo come triplice indiretto. | ||
| + | |||
| + | I file hanno quindi una lunghezza massima. EX4 pero’ risolve indicizzando non i singoli blocchi ma le serie. | ||
| + | |||
| + | Gestione spazio libero | ||
| + | |||
| + | nella struttura indicizzata serve una struttura per tenere conto degli spazi liberi. Si puo’ usare una bitmap per tenere la contabilità degli spazi liberi e quelli utilizzati. | ||
| + | |||
| + | == Lezione del 6 aprile 2017 == | ||
| + | |||
| + | File System. Ext2 e VFAT. Sicurezza, principi generali. | ||
| + | |||
| + | == Lezione del 11 aprile 2017 == | ||
| + | |||
| + | Sicurezza: crittografia (chiave pubblica/chiave segreta) autorizzazione autenticazione firma elettronica. | ||
| + | Virus Worm Cavalli di Troia. | ||
| + | |||
| + | Attacchi buffer overflow e toctou. | ||
| + | |||
| + | == Lezione del 20 aprile 2017 == | ||
| + | |||
| + | (tace per impossibilita' del docente) | ||
| + | |||
| + | == Lezione del 27 aprile 2017 == | ||
| + | |||
| + | P2test (prestest2). | ||
| + | |||
| + | DIscussione specifiche. | ||
| + | |||
| + | == Lezione del 2 maggio 2017 == | ||
| + | == Lezione del 4 maggio 2017 == | ||
| + | * Discussione su proposta da parte degli studenti di modifiche al test di progetto | ||
| + | * Soluzione all'esercizio C1 del 2014-06-16 (Monitor) | ||
| + | * Soluzione all'esercizio 1 del [[http://www.cs.unibo.it/~renzo/so/pratiche/2015.05.29.pdf 2016-05-20]] ( C ) | ||
| + | * Soluzione all'esercizio 2 del 2008-06-13 (Dimostrazione algoritmo di rimpiazzamento a stack) | ||
| + | * Soluzione all'esercizio 1 del [[http://www.cs.unibo.it/~renzo/so/compiti/2013.07.19.tot.pdf 2013-07-19]] (Monitor) | ||
| + | |||
| + | == Lezione del 9 maggio 2017 == | ||
| + | *Esercizio 2 prova teorica 2014.09.24 | ||
| + | *Esercizio g.1 prova teorica 2013.07.19 | ||
| + | *Esercizio c1 e c2 prova teorica 2015.01.20(2014.01.20) | ||
| + | *Esercizio c2 2013.05.30 | ||
| + | |||
| + | == Lezione del 11 maggio 2017 == | ||
| + | == Lezione del 16 maggio 2017 == | ||
| + | * Chiarimenti su svolgimento esame | ||
| + | * Commenti su recenti eventi (WannaCry) | ||
| + | * Visione di programma python per costruzione di stringhe palindrome con monitor | ||
| + | * Correzione esercizio g2 prova teorica 20170209 | ||
| + | * Correzione esercizio 1 [[Prova pratica 2016.09.13]] | ||
| + | * Esercizio c2 prova teorica 20140122 | ||
| + | |||
| + | == Lezione del 18 maggio 2017 == | ||
Latest revision as of 14:15, 15 June 2017
scrivete qui idee, riassunti dei concetti espressi, commenti approfondimenti sulle lezioni.
Lezione del 23 settembre 2016
YY
- Presentazione del corso.
- Strumenti del corso: web, wiki.mailing list
- Indice dei contenuti
- Prove di esame (Scritto, Prova Pratica, Progetto).
- Hardware Software
- Informatica
- Informazione/Dato
- Rivoluzione digitale (secondo rinascimento, Terza rivoluzione Industriale).
- Software Libero
Lezione del 27 settembre 2016
OS:Y
- Organizzazione (martedi' vs. venerdi')
In genere la lezione del martedì sarà più teorica mentre quella del venerdì più orientata agli aspetti pratici di laboratorio. Questa suddivisione potrebbe cambiare in quanto qualche martedì verrà saltato.
- Università
Università = studenti + docenti
- Digitale/Analogico
Digit significa cifra. Nell'informatica è fondamentale il passaggio dal continuo al discreto.
- Binario/Decimale
Nei calcolatori l'informazione è memorizzata utilizzando il sistema binario ...
(in quanto in passato i relè consentivano di avere due stati: " 1 e 0 ": è impreciso, qualcuno sa dare una definizione migliore? Renzo (talk) 12:00, 29 September 2016 (CEST))
In quanto è molto semplice implementare le operazioni aritmetiche con dei circuiti elettronici utilizzando la codifica binaria. Per esempio è possibile creare un circuito che somma due bit con riporto con solo due porte logiche. FedericoB (talk) 17:05, 29 September 2016 (CEST)
- I linguaggi e i problemi dell'Informatica
- Processing dell'informazione (Linguaggi di programmazione)
- Comunicazione (Il problema che i dati che mi servono sono in un altro luogo) (Linguaggi dei protocolli di rete, che però sono dei linguaggi temporizzati)
- Memorizzazione (Il problema che i dati mi serviranno in futuro) (Linguaggio del formato dei dati)
- Conoscenze a lungo, medio e breve termine nell'Informatica.
- BREVE: tecnologia, determinati programmi di sviluppo.
- MEDIO: singoli linguaggi, singoli OS, protocolli di comunicazione.
- LUNGO: algoritmi, informatica teorica, fondamenti costruttivi di reti e di OS.
- Cos'è una distribuzione
E' un antologia di applicazioni e librerie in modo che siano compatibili tra loro.
- Sistema Operativo: perché
Un sistema operativo è un programma che controlla l’esecuzione di programmi applicativi e agisce come interfaccia tra le applicazioni e l’hardware del calcolatore.
E' uno strumento software complesso ed implementabile in diversi modi (monolitico, microkernel, etc.). I microcontroller non hanno OS.
Permette: contabilità delle risorse (consente a sua volta attività di benchmarking); continuità dei servizi; controllo errori
(programmi, dispositivi); multiuser (gli utenti hanno diversi diritti e proprietà sulle risorse); protezione delle attività dei
processi; astrazione file system.
- Struttura a livelli (layer)
---------------
---------------
---------------
OS
---------------L'
hw
---------------L
Consente di: separare la complessità, di avere portabilità.
Ogni livello rappresenta un cambio di linguaggio.
Più aggiungiamo livelli più aumenta il livello di astrazione.
- Programma/processo
Algoritmo: sequenza finita di istruzioni non ambigue, atta a risolvere un problema.
Programma: traduzione degli algoritmi in un linguaggio di programmazione.
Processo: istanza esecutiva di un programma. Il programma è testo statico, quando viene eseguito diviene processo. Possiamo avere uno stesso programma in esecuzione su più processi (e.g apertura di più terminali che eseguono un editor di testo).
System call: richieste di processi al OS. e.g. printf (visto nel codice compilato in assembly tramite gcc -s), invoca write(). vi è una sequenza di azioni del tipo: richiesta di stampa al kernel --> attesa --> risposta.
- Storia dell'Informatica prima dei transistor
La storia dei calcolatori non ha un inizio preciso. Nel 1900 venne trovato sul relitto di una nave greca risalente al II secolo a.C un meccanismo in grado di calcolare i movimenti degli astri, si ipotizza con una sorprendente meccanica. Oggi questo sistema viene conosciuto come Macchina di Anticitera. Negli ultimi anni di ricerche archeologiche e storiche è venuta sempre più in superficie una vena pionieristica nel mondo classico per quanto riguarda lo studio sul calcolo automatizzato e addirittura di automi (si veda Erone di Alessandria). Ma facciamo un salto in avanti di qualche secolo...
Già nel XVII secolo Pascal teorizza e mette in pratica uno strumento in grado di addizionare e sottrarre, e nel 1672 G.W. von Leibniz lo perfeziona con l'aggiunta della moltiplicazione e della divisione. Ma è solamente nei primi anni del 1800 che entra in scena la macchina analitica di Babbage. Estremamente complessa, la macchina era dotata di un sistema di input e di elaborazione dati e di un sistema di output. Ed è con Babbage che nascono le schede perforate. La macchina analitica venne presentata per la prima volta in Italia, durante un convegno torinese del 1840. Tra i vari collaboratori scientifici alla macchina è da annotare la presenza di Luigi Federico Menabrea, che tra le altre cose fu Ministro della Marina Militare, ingegnere e Presidente del Consiglio dei Ministri del Regno d'Italia (1867-1869). Il primo vero programmatore della storia, collaboratrice di Babbage, è Ada Lovelace (figlia del poeta Lord Byron!): progettò un algoritmo in grado di elaborare i numeri di Bernulli.
Nel 1896 viene fondata la Tabulating Machine Company (futura IBM) e agli albori del '900, vari scienziati (trai quali Thomas Edison e Guglielmo Marconi) portarono avanti gli studi sulla valvola termoionica, elemento indispensabile dei primi calcolatori elettronici. La valvola incrementò vertiginosamente i tempi di calcolo ma l'estrema fragilità della stessa causò una serie di problematiche che si risolsero solamente con l'entrata in gioco del transistor.
Lezione del 30 settembre 2016
YC
(Storia dopo l'avvento del transistor)
Tre innovazioni indipendenti:
- Multitasking: Inizialmente ideato per mantenere la CPU occupata con altri processi mentre si faceva Input/Output. Permette di dare l'idea al utente di poter eseguire più processi contemporaneamente anche se questi in realtà sono eseguiti dalla cpu in modo intervallato. Ci sono certi computer che hanno più esecutori e quindi possono realmente eseguire multipli processi contemporaneamente.
- Supporto Multiuser
- Interattività:l'interazione con l'utente cambia il flusso del programma.
Queste tre proprietà sono ortogonali quindi possono esistere nei sistemi varie combinazioni di queste.
Iniziano anche a separarsi i ruoli tra programmatori e utenti.Prima i computer venivano utilizzati solo da chi creava programmi ora anche da chi li utilizza senza avere le conoscenze per crearli.
Il Time Sharing.
Sistemi Paralleli (SIMD/MIMD) Sistemi Real Time
Dal 1969: UNIX.
Il linguaggio C e la portabilità dei sistemi operativi. Caratteristiche del linguaggio C:
- grande controllo sul codice generato
- costrutti per l'elaborazione a basso livello
- supporto per la programmazione strutturata
- linguaggio "leggero": poche parole chiave, I/O gestito tramite librerie
- Il compilatore C è scritto in C.
Portabilità di un compilatore. I cross-compiler.
Il comando UNIX cc (o gcc): un comando unico per attivare l'intera toolchain per generare un eseguibile.
Il punto e virgola trasforma espressioni in istruzioni (terminatore).
1975? l'avvento dei personal computer. (in realtà il primo PC forse e' la Perrottina Olivetti del 1964).
Compiti a casa: Portare esperimenti in C ritenuti "difficili".
Renzo (talk) 10:41, 1 October 2016 (CEST)
Lezione del 7 ottobre 2016
Audio Lezione: 7\10\16
- Esempi di programmi in linguaggio C
Abbiamo commentato i programmi dal 1.1 al 1.7 che si possono trovare in questa pagina.
- Economia Push/Economia Pull
Nell'economia push si basa la produzione sulla previsione di domanda e la si cerca di aumentare tramite la pubblicità. Questa è stata la principale metodologia utilizzata nei secoli scorsi. Al giorno d'oggi si sta facendo avanti un differente approccio chiamato "economia pull" dove la produzione è basata sulla domanda effettiva. Per esempio per richiedere un finanziamento per l'economia push l'approccio comune è tramite una banca a cui si chiede un prestito in base alle previsioni di ricavo. Invece nell'economia pull è esemplare il fenomeno del crowdfounding dove si riceve un finanziamento dalla "folla" cioè da un gruppo di persone che dona una piccola parte di denaro ciascuna in base al reale interesse per il prodotto/servizio.
- Sistemi Operativi e parallelismo
Più processi si dicono in esecuzione concorrente quando accedono a risorse condivise.
Un programma è multithread quando tutti i thread condividono la stessa memoria. Ogni thread deve avere un suo stack.
La concorrenza si studia in particolare in sistemi operativi in quanto un sistema operativo multitasking è un sistema concorrente.
Concorrenza di processi in architetture SMP (Symmetric multiprocessor system) e non. (RD: non mi pare di aver spiegato cosa sia l'SMP)
Simulazione del fenomeno della race condition. Si ha race condition quando un programma concorrente può puo' produrre diversi risultati se eseguito piu' volte per colpa della diversa evoluzione temporale delle elaborazioni.
Per risolvere questo dovremmo raggruppare le istruzioni in sezioni critiche (sequenze inscindibili di istruzioni che devono essere eseguite come se fossero atomiche, tutta la sequenza o niente).
- Architettura a livelli e virtualizzazione
Dato un A e un A’ e riusciamo a usare A’ come A, allora A’ lo possiamo chiamare A virtuale.
L'idea che alla base delle macchine virtuali è di creare un interprete di un ISA differente o uguale a quello del sistema in modo da virtualizzare una reale macchina hardware e quindi poterla usare per gli stessi scopi di una macchina reale. E' quindi possibile, per esempio, installare sistemi operativi su hardware virtuale.
L'insieme dei componenti hardware virtuali e il software installato su di questi prende il nome di macchina virtuale.
Uno dei principali vantaggi, oggi molto utilizzato in ambito cloud, è quello di poter suddividere facilmente risorse hardware fisiche, per esempio spazio su disco e potenza di elaborazione, tra macchine virtuali differenti.
- Laboratorio di cross-compiling
Nel ultima parte della lezione abbiamo fatto un esperimento sulla portabilità dei compilatori.
Abbiamo a disposizione un linguaggio ad alto livello che chiameremo L, due interpreti hw0 e hw1 per linguaggi a basso livello che chiameremo lhw0 e lhw1 e infine due compilatori L->lhw0 uno scritto in python e l'altro in L.
Se compiliamo con il compilatore scritto in python (abbiamo un interprete python installato sulla macchina che stiamo utilizzando) il compilatore scritto in L otteniamo un compilatore scritto in lhw0 L->lhw0.
Se ora modifichiamo il compilatore scritto in L L->lhw0 in modo che crei codice per hw1 (basta modificare gli indici numerici delle istruzioni) otteniamo un compilatore in L L->lhw1. Se lo compiliamo con il compilatore L->lhw0 otteniamo un cross-compiler scritto in lhw0 L->lhw1, cioè un compilatore che crea codice eseguibile su una macchina diversa da quella attuale.
Se ora utilizziamo il cross compiler L->lhw1 per compilare il compilatore scritto in L L->hw1 otteniamo invece un compilatore che può essere eseguito su hw1.
A questo punto su hw1 potremmo utilizzare l'ultimo compilatore creato per compilare sempre il compilatore scritto in L L->hw1 ma vedremo che otterremo sempre lo stesso file perché avremo raggiunto il limite.
Il materiale per poter replicare l'esperimento sulla portabilità dei compilatori è qui.
Renzo (talk) 13:42, 8 October 2016 (CEST)
Lezione del 11 ottobre 2016
- C
#include <stdio.h>
void dump (void* f, size_t len){ //size_t is the sizeof() return type
unsigned char *s = f;
size_t i;
for (i = 0; i < len; i++)
printf("%02x ",s[i]); //%02x means print at least 2 digits and add 0's if there are less
printf("\n");
}
int main(){
int v[] = {1, 2, 3, 4}; //v is (int*) 0x32ef...
v[2] = 42; //*((int*) 0x32ef) + 2 = 42, moves the address by 2 "positions", aka 4+4 bytes
v[2] = 0x33;//(int*) 0x32ef.. = 0x33 (i.e.) 4 = 42
char s[] = "ciao";
int t[] = {0x63, 0x69, 0x61, 0x6f, 0x00}; //ciao in ASCII hex. if int OUT:'c'. if char OUT:"ciao"
char u[] = {99, 105,97, 111, 0 }; //ciao in ASCII dec. OUT:"ciao"
char *q = "ciao";
char *w = "mare";
printf("%s\n", s);
printf("%s\n", t);
printf("%s\n", u);
dump(s, sizeof(s));
dump(t, sizeof(t));
dump(q, sizeof(*q)); //*q size is 1B (it points to 1 char). OUT: 63('c')
dump(q, sizeof(q)); //q size is 8B. OUT: 5B of "ciao" + 3B of contiguous string "mare"
}
OUTPUT:
ciao c ciao 63 69 61 6f 00 63 00 00 00 69 00 00 00 61 00 00 00 6f 00 00 00 00 00 00 00 //int are 4B, char 1B, so we have empty bytes. Little endian pattern is evident. %s allow to print untill the first null, so printf prints just 'c' with int declaration of t[] 63 63 69 61 6f 00 6d 61 72 // 6d = m, 61 = a, 72 = r.
- Assioma di finite progress.
"Tutto è vero purchè ogni statement abbia durata sconosciuta, ma finita"
- Modalità di concorrenza.
1- Inconsapevolmente concorrenti: ogni processo elabora ciò per cui è stato creato. Il kernel si occupa di coordinazione e comunicazione.
2- Indirettamente concorrenti: processi che accedono a file condivisi.
3- Consapevolmente concorrenti: il programma ha diversi processi in esecuzione.
- Convenzioni usate nel corso (e negli esami) relative alle istruzioni atomiche
Le istruzioni atomiche vengono compiute in modo indivisibile, garantendo che l'azione non interferisca con altri processi durante la sua esecuzione. Vengono rappresentate nel seguente modo:
<istruzione atomica>
Anche gli statement sono istruzioni atomiche(escluso il caso long long).
- Proprieta' di Safety e Liveness
-Safety: se il programma evolve, evolve bene(S)
"Something good happens"
-Liveness: il programma va avanti(L)
"Something eventually happens"
- Problema del consenso.
Il problema è così definito: ci sono n processi, ognuno propone un valore. Al termine tutti i processi devono accordarsi su di 1 dei valori proposti.Il suddetto problema è risolvibile se e solo se vengono rispettate le seguenti proprietà (2 di Safety + 1 di Liveness)
Proprietà:
S(1)- Tutti i processi devono ritornare lo stesso valore
S(2)- Ogni processo corretto decide uno tra i valori proposti
L(1)- Ogni processo corretto deve dare una risposta
w/o S(1): f(x) = x
w/o S(2): f(x) = 42
w/o L(1): f(x) = while(1)
- w/o = without
- Problemi delle elaborazioni concorrenti. Prima definizione (non formale) di Deadlock e Starvation
Introduzione alla notazione per la rappresentazione dei processi concorrenti
ESEMPIO 1.0
process p {
...
...
}
process q {
...
...
}
Due processi eseguiti in concorrenza.
... cobegin ... // ... // ... coend
cobegin e coend indicano la sezione di codice con le istruzioni (rappresentate da "..." e separate da "//")che verranno eseguite in concorrenza.
ESEMPIO 1.1 - Merge sort
cobegin sort(v[1 : N]) // sort(v[N : N]) // merge(v[1 : N]), v[N : M]) coend
Se isoliamo le istruzioni senza considerare cobegin e coend, lo pseudocodice è corretto. Se consideriamo anche cobegin e coend il programma esegue la funzione di merge() in concorrenza con le due chiamate a sort(), utilizzando risorse in comune e pertanto cercando di ordinare elementi non ancora ordinati nelle due metà dell'array. Se spostiamo l'invocazione di merge al di fuori della sezione cobegin ... coend, lo pseudocodice (vedi in basso) è corretto.
cobegin sort(v[1 : N]) // sort(v[N : N]) coend merge(v[1 : N]), v[N : M])
In particolare nella programmazione concorrente si devono affrontare due problemi che riguardano la liveness, parliamo di deadlock e starvation.
DEADLOCK: uno o più processi non possono continuare l'esecuzione perchè ognuno di essi è in attesa che gli altri facciano qualcosa
ESEMPIO 1.2
process p {
while 1:
prendi a
prendi b
calcola f(a,b)
lascia a
lascia b
}
process q {
while 1:
prendi a
prendi b
calcola f(a,b)
lascia a
lascia b
}
Supponiamo di invertire l'ordine di prendi a e prendi b nel processo p. Dopo che entrambi i processi eseguono la prima istruzione lo scenario che si sviluppa è il seguente: al processo p serve la risorsa a, presa dal processo q, al quale servirebbe la risorsa b, presa dal processo p. I processi aspettano a vicenda che uno rilasci la risorsa che possiede l'altro. Risorsa necessaria ad entrambi i processi per eseguire l'istruzione (f(a,b)) che le richiederebbe entrambe. I processi sono deadlocked.
STARVATION: quando un processo attende una risorsa indefinitamente, e questa non gli viene mai allocata
ESEMPIO 1.3
process p {
while 1:
prendi a
calcola f(a)
lascia a
}
process q {
while 1:
prendi a
calcola f(a)
lascia a
}
Supponiamo che i processi per realizzare "prendi a" verifichino la disponibilità di a tramite polling (provando ripetutamente se a è libero). Il processo q può essere sfortunato e non riuscire mai ad avere accesso ad a (tutte le volte che cerca di "prenderlo" lo troverà impegnato da p). Il processo q è in starvation.
ESEMPIO 1.4 "Supponiamo di avere tre processi (P1, P2, P3) i quali richiedono periodicamente accesso alla risorsa R. Consideriamo la situazione nella quale P1 è in possesso della risorsa, e sia P2 che P3 attendono per quella risorsa. Quando P1 esce dalla sua sezione critica, a P2 o P3 dovrebbe essere permesso l'accesso a R. Assumiamo che il SO garantisca l'accesso a P3 e che P1 richieda nuovamente la risorsa prima che P3 termini la sua sezione critica. Se il SO dovesse garantire l'accesso a P1 dopo che P3 abbia finito, e successivamente dovesse garantire alternativamente a P1 e P3 l'accesso alla risorsa, allora P2 potrebbe vedersi indefinitamente negato l'accesso alla risorsa, sebbene non vi sia una situazione di deadlock" (Stallings W.(2015). Operating System: internals and design principles. (8th ed). Pearson)
Problema: posso creare sezioni critiche, tramite la programmazione, senza aiuti hardware?
ESEMPIO
process p /*enter_cs*/ A = A + 1 /*exit_cs*/
process q /*enter_cs*/ A = A - 1 /*exit_cs*/
Le 4 proprietà della critical section(CS)
SAFETY(1): una operazione all'interno della CS
ESEMPIO
process p while 1: /*enter_cs*/ A = A + 1 /*exit_cs*/ ... <--- process q deve poter "entrare" qui
LIVENESS(1): no deadlock
LIVENESS(2): no starvation
LIVENESS(3): no useless wait
Dekker(1st attempt) //KEY: turno
turn = p //var globale condivisa
process p{
while (turn != p)
;
/*A = A + 1*/
turn = q
...
}
process q{
while(turn != q)
;
/*A = A - 1*/
turn = p
...
}
Non rispetta la proprietà di liveness(3), infatti uno dei due processi può dover attendere a lungo il suo turno eseguendo ciclicamente l'empty statement all'interno del corpo del while. Questa situazione può verificarsi se l'altro processo fallisce dentro o fuori la sua CS (in questo caso l'attesa è infinita). Inoltre visto che i processi si alternano strettamente nell'utilizzo della loro critical section, il ritmo di esecuzione è dettato dal processo più lento dei due.
Dekker(2nd attempt) //KEY: flag, ma senza turno
inp = false
inq = false
process p{
while 1:
while(inq)
;
inp = true
/*A = A + 1*/
inp = false
...
}
process q{
while 1:
while(inp)
;
inq = true
/*A = A - 1*/
inq = false
...
}
In questo caso se uno dei processi fallisce fuori dalla CS (dopo aver settato il flag a false) l'altro processo non viene bloccato. Se invece un processo fallisce nella sua CS oppure dopo aver settato il flag a true allora l'altro processo resta bloccato indefinitamente. Non è garantita inoltre la mutua esclusione in quanto entrambi potrebbero essere al contempo nelle loro rispettive CS, ad esempio:
p valuta la condizione del while e trova inq a false
q valuta la condizione del while e trova inp a false
p assegna true a inp ed entra nella sua CS
q assegna true a inq ed entra nella sua CS
....entrambi sono nella rispettiva CS --> no liveness(1)
Dekker(3nd attempt) //KEY: come 2nd ma con due istruzioni scambiate di ordine
process p{
while 1:
inp = true
while(inq)
;
/*A = A + 1*/
inp = false
...
}
process q{
while 1:
inq = true
while(inp)
;
/*A = A - 1*/
inq = false
...
}
Scambiando l'ordine di due istruzioni vi è la mutua esclusione, tuttavia se entrambi i processi assegnano true al loro rispettivo flag, prima di valutare la condizione del while, entrambi resteranno all'interno del while in attesa che l'altro processo "esca dalla CS" (non vi è mai entrato) --> deadlock
Dekker(4nd attempt) //KEY: flag + delay
process p{
while 1:
inp = true
while(inq){
inp = false; < delay >; inp = true;
}
/*A = A + 1*/
inp = false
...
}
process q{
while 1:
inq = true
while(inp){
inq = false; < delay >; inq = true;
}
/*A = A - 1*/
inq = false
...
}
In questo caso il settare il proprio flag a true è indice del desiderio di entrare nella propria CS. Vi è ancora mutua esclusione. Se però dovesse verificarsi una sequenza del tipo:
p imposta flag inp a true
q imposta falg inq a true
p valuta la condizione del while
q valuta la condizione del while
p imposta flag inp a false
q imposta flag inq a false
p imposta flag inp a true
q imposta flag inq a true
allora c'è la possibilità che si ripeta all'infinito (entrambi i processi potrebbero rimanere nel while). Essendo però una condizione che dipende dalla velocità relativa dei due processi, esiseranno delle situazioni nelle quali uno dei due processi potrà entrare, così come vi saranno delle situazioni nelle quali nessun processo avrà accesso alla propria CS --> livelock
Dekker...finally //KEY: flag + turni ("cambio delay con turno)
needp = false
needq = false
turn = p
process p{
while 1:
needp = true
while (needq) {
needp = false
while(turn == q)
;
needp = true
}
/*A = A + 1*/
needp = false
turn = q
...
}
process q{
while 1:
needq = true
while(needp) {
needq = false;
while(turn == p)
;
needq = true
}
/*A = A - 1*/
needq = false
turn = p
...
}
In questo caso il processo che vuole entrare nella sua CS ne manifesta il bisogno settando need a true. Se entrambi i processi entrano nel corpo del while il tie-break è espletato dal while la cui condizione è un turn che sarà uguale soltanto ad uno dei due processi (in questo caso turn è inizializzata a p), e dunque non si verificherànno situazioni di deadlock o livelock.
- Proprietà della sezione critica
Mutua esclusione
Assenza di deadlock
Assenza di starvation
Assenza di delay non necessari
- La test&set
E' un istruzione atomica per impostare il valore di una variabile a 1 (lock) ma ritornare il vecchio valore. Questa istruzione può essere utilizzata per gestire sezioni critiche.
Il valore ritornato dalla test and set viene comparato a 1, se è uguale si aspetta altrimenti si procede.
In questo modo il primo processo che cercherà di entrare nella sezione critica ci riuscirà e imposterà il lock a 1, gli altri processi si troveranno il lock a 1 e dovranno aspettare. Quando il primo processo avrà finito ripristinerà il vecchio valore di lock e permetterà a uno degli altri processi di eseguire la test and set e di entrare nella sezione critica.
Altri argomenti trattati che non sono stati qui riportati in forma di appunti: Gestione algoritmica della critical section. Algoritmo di Dekker. Gestione architetturale della critical section.
Renzo (talk) 10:35, 17 October 2016 (CEST)
Lezione del 14 ottobre 2016
Audio Lezione: 14\10\16
- Sistemi Operativi per elaboratori multiprocessore SMP/non SMP
- Macchine di von Neumann (e di Harvard).
- Il bus.
- Interrupt e Trap
- Gestione degli interrupt
- Mascheramento degli interrupt
- Interrupt Nidificati
- DMA
- Device a carattere e device a blocchi
- System call come trap.
- La gerarchia delle memorie
- cache
Lezione del 18 ottobre 2016
Audio Lezione: 18/10/16
Argomenti trattati:
- Implementazione in C della Test&Set, degli Algoritmi di Dekker e Peterson.
Codice sorgente disponibile qui.
- Definizione di Semaforo.
Un semaforo è una variabile intera che può essere modificata solo da 2 operazioni atomiche: P(Proberen) e V(Verhogen).
P aspetta che il valore sia minore o uguale a zero. Quando lo diventa decrementa il valore.
S incrementa il valore.
- Invariante del Semaforo.
Il numero di Proberen deve essere minore o uguale al numero di Verhogen più il valore d'inizializzazione del semaforo.
In questo modo si può gestire per esempio l'allocazione di risorse. Il semaforo viene inizializzato al numero di risorse e ogni volta che un processo ha bisogno della risorsa esegue un proberen, quindi decrementa il valore se la risorsa è disponibile. Quando un processo rilascia la risorsa esegue un verhogen.
- Esempio: implementazione di sezione critica e di semplice sincronizzazione con semafori.
Lezione del 21 ottobre 2016
- Make
Make è un sistema per la compilazione intelligente dei programmi.
Permette invece di compilare tutto il programma tutte le volte di compilarne solo una parte, solo quella che è stata modificata.
Per capirne il funzionamento è utile un parallelismo con le ricette di cucina. Si specificano dei target che sono gli obbiettivi della ricetta.Per fare una ricetta servono degli ingredienti e magari quegli ingredienti hanno a loro volta delle ricette. Make allo stesso modo definisce dei target che possono avere come dipendenze altri target.
Nel installazione del programma il programma ./configure cerca nel sistema se le librerie da cui è dipendente il programma sono presenti.
- Git
Git è un sistema di versioning, serve a tener traccia delle modifiche apportante a un progetto nel tempo. E' utile per collaborare a un progetto condiviso.
Possibilità per ogni membro del repository di lavorare in maniera indipendente e poi aggiornare il progetto comune.
Ce ne sono stati tanti di sistemi di versioning tipo SVN, Mercurial ma attualmente Git è il più utilizzato.
Git non serve solo per scrivere programmi ma per esempio anche libri, in modo collaborativo.
Git è completamente distribuito, non esiste in un repository una copia principale e delle copie secondarie ma ogni copia può essere principale.
Per iniziare un repository git si utilizza il comando git init.
Per aggiungere un file al repository si utilizza il comando git add.
Ma ad ogni singola modifica git non aggiorna automaticamente il repository ma è l'utente che tramite il comando git commit indica che una certa versione del progetto deve essere salvata.
Il comando git log serve a visualizzare la storia del repository.
Il comando git diff serve a vedere la differenza tra ciò che è nel repository e le modifiche di cui non si è ancora fatto il commit.
Dopo aver dato il comando add si dice che i file sono 'on stage' prima del commit.
Il comando git checkout serve a spostarsi nella storia del repository.
Il comando git clone serve a copiare un repository remoto.
Il comando git push serve a inviare le modifiche al repository remoto mentre il comando git pull serve a ricevere le modifiche più aggiornate dal repository remoto.
Il merge è il processo in cui uno degli utenti che crea un conflitto deve "a mano" scegliere quali parti dei due commit in conflitto vuole tenere.
Git è utile per trovare i bug che non erano presenti in versioni precedenti del progetto. Si può tornare alla versione precedente stabile e avanzare nella storia fino a trovare una versione instabile. A questo punto è probabile che l'origine del bug sia nelle modifiche che hanno creato questa versione instabile.
Github è una piattaforma di repository dove possono essere mantenuti dei progetti gratuitamente se sono con licenza libera.
In una directory in cui è presente un repository git e sempre la presente la cartella .git dove il sistema di versioning mantiene il database della storia.
Lezione del 25 ottobre 2016
Audio Lezione: 25/10/16
Argomenti trattati:
- Semafori fair
Un semaforo è "fair" quando tende a non sbloccare dallo stato di attesa sempre lo stesso processo ma cerca di distribuire la possibilità di esecuzione a più processi.
- Problemi classici della concorrenza risolti con semafori
- Produttore/consumatore
- Due processi: produttore e consumatore. Il produttore genera continuamente dei valori e il consumatore continuamente li legge. Il consumatore deve leggere i valori nello stesso ordine in cui il produttore li genera.
- Un meccanismo di sincronizzazione e richiesto perchè sorgono immediatamente due problemi:
- Produttore troppo veloce: il consumatore non fa in tempo a consumare il valore e c'è la possibilità che i valori non ancora letti vengano sovrascritti.
- Consumatore troppo veloce: possibilità che il consumatore legga un valore che ha già letto perchè il produttore non ha fatto in tempo a produrne uno nuovo.
- Per risolvere il problema utilizziamo due semafori: empty e full.
- Il produttore aspetta che il segnale del semaforo empty (Proberen), scrive il valore e dà segnale sul semaforo full (Verhogen).
- Il consumatore aspetta il segnale del semaforo full (Proberen), legge il valore e dà segnale sul semaforo empty (Verhogen).
- Buffer-limitato
- Simile al problema produttore/consumatore ma qui lo scambio avviene tramite un buffer limitato.
- In questo modo nel caso di rallentamento temporaneo del consumer il producer non deve aspettare ma può produrre più unità e viceversa nel caso di rallentamento del producer, se il buffer ha più di un elemento, il consumer può utilizzare il tempo in attesa del producer per consumare più dati.
- Nel caso il buffer sia completamente pieno/vuoto rimangono comunque i problemi di sincronizzazione tipici del problema: il producer non deve sovrascrivere dei valori che il consumer non ha ancora letto e il consumer non deve leggere più volte lo stesso valore se il producer non è stato abbastanza veloce da cambiarlo.
- Come soluzione al problema si può utilizzare un coda circolare. Il produttore esegue una enqueue e il consumatore una dequeue.
- Il problema può essere generalizzato facilmente a produttori/consumatori multipli ma in questo caso dobbiamo creare un semaforo per rendere atomiche la enqueue e la dequeue altrimenti incorriamo in una race condition nel accesso alla coda.
- Due processi: produttore e consumatore. Il produttore genera continuamente dei valori e il consumatore continuamente li legge. Il consumatore deve leggere i valori nello stesso ordine in cui il produttore li genera.
Lezione del 28 ottobre 2016
Implementazione dei semafori
Un processo che esegue una Proberen in teoria dovrebbe aspettare continuando a controllare se può entrare nella sezione critica. Questo meccanismo si chiama "busy waiting" e consuma molte istruzioni della CPU.
Il busy waiting è diverso dal polling in quando il polling prevede di eseguire altre azioni mentre si aspetta tra un tentativo e l'altro.
Di solito si utilizza il busy waiting solo quando il tempo di lock di un processo è molto breve. Questo perchè anche se esoso di risorse del processore il busy waiting non comporta un context switch, cioè salvare tutto lo stato del processo in memoria, e quindi permette di risparmiare memoria.
Se invece il tempo di lock è più lungo allora è preferibile utilizzare un context-switch dove il processo si blocca da solo e chiama un processo di blocking che lo mette in una coda di attesa associata al semaforo che sta aspettando. Il controllo passa poi allo scheduler della CPU che seleziona un altro processo da eseguire.
Le primitive suspend and wakeup indicano rispettivamente lo spostamento di un processo nella/dalla coda dei processi ready.
- nei kernel monoprocessore
- Implementazione dei semafori tramite mutex che possono essere a loro volta implementate con un sistema di mascheramento degli interrupt.
- nei kernel multiprocessore
- Utilizzo di soluzioni hardware come test and set. Sono soluzioni che utilizzano il busy waiting ma in questo caso solo per rendere atomico le operazioni del semaforo, che sono poche istruzioni.
Certe implementazioni dei semafori potrebbero permettere di far andare il valore in negativo. Questo serve per misurare il numero dei processi in attesa di quel semaforo.
Il problema della cena dei filosofi:
5 filosofi passano la loro vita pensando e mangiando. Condividono un tavolo circolare con 5 sedie e ogni sedia appartiene a un solo filosofo. Alla sinistra e alla destra di ogni piatto c'è una bacchetta per un totale di 5 bacchette. La bacchetta destra che un filosofo usa per mangiare viene quindi utilizzata come bacchetta sinistra dal filosofo alla sua destra e simmetricamente è uguale per il filosofo che siede a sinistra.
Ogni tanto un filosofo smette di pensare e cerca di prendere le rispettive bacchette, se ci riesce può mangiare e poi rilasciare le bacchette.
Questo problema è un modello di problema ad accesso a insiemi di risorse. Mentre nel produttore/consumatore e buffer limitato gli attori in gioco avevano la necessità di avere l'accesso esclusivo a una sola risorsa in questo problema è richiesto l'accesso a insiemi di risorse (le bacchette) le cui parti possono essere desiderate da altri richiedenti.
- soluzione con contesa sulle posate e casi di deadlock
- Poniamo un semaforo per ogni bacchetta. Può succedere però, se nel implementazione i filosofi "prendono in mano" prima la bacchetta destra e poi quella sinistra, che tutti prendono in mano contemporaneamente la bacchetta destra e rimangono in un'attesa infinita della bacchetta sinistra che non gli verrà mai rilasciata perché anche il rispettivo filosofo alla propria sinistra è in attesa.
Questo è un caso di deadlock. - Una soluzione può essere quella di imporre che un filosofo sia "mancino" cioè prenda prima la bacchetta a sinistra e poi la destra.
- soluzione con acquisizione atomica di entrambe le posate, casi di starvation
- Un'altra soluzione è quella di rendere atomico l'acquisizione di entrambe le posate.
- Può succede che 4 filosofi compiano una "congiura", cioè siano d'accordo a non lasciar risorse a un quinto filosofo. Questo è un caso di starvation e non è irreale in quando i 4 filosofi potrebbero essere processi malevoli che siano stati programmati di proposito per questo.
System Call:
- POSIX.
- Il POSIX è uno standard (IEEE 1003) che definisce le signature delle system call. Un sistema operativo deve rispettare il POSIX per essere definito "Unix-like".
- Di solito i parametri delle system call sono pensati per essere contenuti in un registro. Quasi sempre le system call ritornano un intero: 0 se la procedura è stata eseguita correttamente, -1 se c'è un errore. Quando una system call ritorna -1 la variabile "globale" errno (error number) contiene il codice di errore. La variabile errno non è realmente globale perché ne esiste una per ogni processo.
- Unix è un sistema operativo file-system centrico quindi quando facciamo input/output anche da periferiche come stampanti e lettori CD usiamo le system call per la scrittura/lettura dei file.
- Un catalogo delle system call principali può essere trovato qui.
- fork/exec
- fork e exec sono system call importanti e servono per creare un nuovo processo:
- fork: genera un processo clone di quello che ha chiamato fork.
- exec: "cambia" il codice eseguito dal processo corrente.
- Quindi per "aprire un nuovo programma" si utilizza una fork seguita da un exec.
Lezione del 4 novembre 2016
Audio Lezione: 4/11/16
- Problema della Cena dei filosofi. Soluzione con acquisizione atomica delle bacchette (con starvation)
- Tecnica del passaggio del testimone (Passing the Baton).
- Non uscire dalla mutua esclusione se c'è qualcun altro che vuole entrarci e semplicemente fare in modo che lui l'acquisisca. La mutua esclusione termina solo se non c'è nessuno che più la richiede.
ESEMPIO IMPLEMENAZIONE BATON
void baton(int i) {
int j;
for (j=1; j<5; j++) {
if(philo_status[(i+j)%5] == 'W' && philo_status[(i+j+1)%5] != 'E' && philo_status[(i+j+4)%5] != 'E') {
semaphore_V(philowait[(i+j)%5]);
return;
}
}
semaphore_V(mutex);
}
- Cena dei filosofi, acquisizione atomica delle bacchette con passaggio del testimone.
- Implementazione della congiura dei filosofi
- Le system call di gestione file (open, read, write, close, lseek)
Quando lavoriamo con dei file dobbiamo sempre specificare se vogliamo solo leggerli oppure anche scrivere, magari in append mode. Ci sono quindi varie modalità con cui possiamo interagire con i file.
Un utente potrebbe essere autorizzato a gestire il file in certe modalità oppure no.
Il descrittore di un file è un intero.
Le system call, a differenza delle chiamate di funzioni di libreria, non sono bufferizzate.
ESEMPIO
Se si decommenta printf stampa 2 volte hello world perchè la stringa resta nel buffer.
Se si decommenta write stampa 1 volta hello world.
Per vedere le chiamate di sistema effettuate in fase di esecuzione, compilare il codice sorgente e poi utilizzare strace -f "eseguibile".
#include<stdio.h>
#include<unistd.h>
int main(int argc, char* argv[]){
//printf("hello world"); //if you ends the strings with \n is like to "fflushing" the buffer
//write(1, "hello world", 11); // 1 and 11 are file descriptors
switch(fork()) {
case 0: //child
break;
default: //parent
wait(NULL);
break;
case -1: //error
break;
}
printf("\n");
return 0;
}
Copia il file passato come primo argomento (argv[1]) nel file passato come secondo argomento (argv[2]), se quest'ultimo non esiste, allora lo crea.
#include<stdio.h>
#define BUFSIZE 2048
char buffer[BUFSIZE];
int main(int argc, char *argv[]){
int fdin = open(argv[1], O_RDONLY);
int fdout = open(argv[2], O_WRONLY | O_CREAT | O_TRUNC, 0666); //0666 is the umask used to modify the permissions of new files
int n;
while((n = read(fdin, buffer, BUFSIZE)) > 0)
write(fdout, buffer, n);
close(fdin);
close(fdout);
return 0;
}
umask
Con la open possiamo usare dei permessi al massimo per quelli garantiti dal umask.
Un numero composto da quattro cifre ottali. Controlla la maschera di creazione dei file. I bit di permesso contenuti nella maschera NON vengono settati nel nuovo file creato. Corrisponde all'opereazione:
R:(D &(~M))
Può essere vista come una sottrazione, i bit accesi nella umask vengono spenti nel file creato.
e.g. se i permessi di default corrispondono a 0666(D) e la maschera corrisponde a 0022(M), R è uguale a 0666-0022 = 0644. Infatti
0022 = |000|000|010|010| ~0022 = |111|111|101|101|(7755) 0666 = |000|110|110|110| ~0022 & 0666 = |000|110|100|100|(0644)
Tabella significato cifre umask
OTTALE BINARIO SIGNIFICATO 0 000 Nessun permesso 1 001 Solo esecuzione 2 010 Solo scrittura 3 011 Scrittura ed esecuzione 4 100 Solo lettura 5 101 Lettura ed esecuzione 6 110 Lettura e scrittura 7 111 Lettura, scrittura ed esecuzione
I permessi sono rappresentati in simboli come segue:
r: read w: write x: execute
umask - S da shell per visualizzare la umask attuale con rappresentazione simbolica
ls -l "nomefile" da shell per visualizzare i permessi del file in notazione simbolica: '-' seguito da 3 triple che indicano i permessi di accesso per ugo, ovvero, rispettivamente, per user, per group, per other.
ESEMPIO
-rw-r--r--
- File aperti durante fork/exechttps://www.kernel.org/
I file aperti vengono ereditati dai processi figli.
Processo padre e processo figlio condividono lo stesso offset nei file comuni. In questo modo si evita di sovrascriversi a vicenda. Ogni volta che il padre o il figlio scrivono sul file aggiornano l'offset comune.In questo modo se l'altro processo vuole anche lui scrivere in quel file partirà dal offset aggiornato e non sovrascriverà i dati scritti dal altro processo.
- La system call dup e la ridirezione
E' possibile fare in modo che più file descriptor siano associati a un unico file (per la precisione a un unica file table, che serve per gestire un file).
La system call dup permette di fare ciò. Ritorna un nuovo file descriptor che punta a una file table già esistente.
Possiamo quindi "ridirezionare" l'output o l'input di un processo figlio modificando i file descriptor prima di creare il processo figlio. Per esempio possiamo modificare un file descriptor che puntava a un normale file in modo che punti a un file di standard output e quindi anche se al processo figlio sembrerà di scrivere in un normale file starà scrivendo nel terminale.
ESEMPIO
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<stdio.h>
#include<unistd.h>
int main(int argc, char * argv[]){
int fdout;
if(argc > 1);
fdout = open (argv[1], O_WRONLY | O_CREAT | O_TRUNC, 0666);
switch(fork()) {
case 0: //child
dup2(fdout, 1); // duplica descrittore file, posso ridirezionare l'output. E' come fare '>' dalla shell
execlp(”ls”, “-l”, 0);
close(fdout);
break;
default: // parent
wait(NULL);
break;
case -1: // error
break;
}
printf(“\n”);
return 0;
}
Lezione del 8 novembre 2016
Codice per la congiura dei filosofi
#include <stdio.h>
#include <stdint.h>
#include <pthread.h>
#include "semaphore.h"
semaphore philowait[5];
semaphore mutex;
semaphore cospsem;
char philo_status[]="TTTTT";
void baton(int i){
int j = 0;
//iterate through remaining philosophers
for(j = 1; j < 5;j++){
//if there's any waiting philosopher, and no other philosophers(on his left and right side) are eating
if(philo_status[(i+j)%5]=='W' && philo_status[(i+j+1)%5]!= 'E' && philo_status[(i+j+4)%5]!='E'){
semaphore_V(philowait[(i+j)%5]);
return;
}
}
semaphore_V(mutex);
}
void ok2eat(int i){
semaphore_P(mutex);
philo_status[i]='W';
if(philo_status[(i+1)%5] == 'E' || philo_status[(i+4)%5] == 'E'){
semaphore_V(mutex);
semaphore_P(philowait[i]); //wait for baton
}
philo_status[i] = 'E';
printf("philo eating: %d |%s|\n",i,philo_status);
baton(i);
}
void ok2think(int i){
semaphore_P(mutex);
philo_status[i] = 'T';
printf("philo thinking: %d |%s|\n",i,philo_status);
baton(i);
}
void conspiracy_in(){
static int first_time = 1; //this variable's value is preserved between calls to this function
semaphore_P(mutex);
if(first_time){
//first conspirator entering here will act like nothing happened
first_time = 0;
}
else{
//conspire
semaphore_V(cospsem);
}
semaphore_V(mutex);
}
void conspiracy_out(){
semaphore_P(cospsem);
}
void *philo(void *arg) {
int i = (uintptr_t)arg;
while (1) {
//thinking/still thinking
usleep(random() % 200000);
ok2eat(i);
//eating
//conspirators need to be synchronized to conspire
if(i==1 || i==3) conspiracy_in();
usleep(random() % 200000);
if(i==1 || i==3) conspiracy_out();
ok2think(i);
//thinking again
}
}
int main(int argc, char *argv[]) {
int i;
pthread_t philo_t[5];
srandom(time(NULL));
mutex = semaphore_create(1);
cospsem = semaphore_create(0);
for (i=0; i<5; i++)
philowait[i]=semaphore_create(0);
for (i=0; i<5; i++)
pthread_create(&philo_t[i], NULL, philo, (void *)(uintptr_t) i);
for (i=0; i<5; i++)
pthread_join(philo_t[i], NULL);
}
- Problema dei lettori e scrittori
- Spesso quando gestiamo la concorrenza all’accesso a strutture dati separiamo i ruoli di solo lettori con anche quello di scrittori (che per fare ciò possono dover anche leggere).
- Mentre che per i lettori non c’è un limite a quanti contemporaneamente possono avere accesso alle informazioni, gli scrittori devono avere accesso esclusivo alla struttura dati.
- Questo perché incorriamo in una race-condition solo quando modifichiamo la struttura dati.
- Dare precedenza di accesso a una categoria o all’altra porta starvation nella categoria con meno priorità.
- Una soluzione che abbiamo dato è quella di dare esclusività ai ruoli a turno:
- dopo che uno scrittore ha finito di scrivere garantisce l’accesso prima a tutti i lettori in attesa e se non sono presenti agli scrittori in attesa. Per i lettori è il contrario: dopo che l’ultimo lettore ha finito di leggere garantisce l’accesso a uno dei possibili scrittori in attesa e se non ce ne sono ai lettori.
- La soluzione in C al problema lettori e scrittori può essere trovata qui.
- Semafori Binari(Introduzione)
- Un semaforo binario è un semaforo ordinario che rispetta la seguente invariante: nP<=nV+Init<=nP+1, ovvero è un semaforo che può assumere solo valori 0 o 1.
- Si può dimostrare che i semafori ordinari sono espressivi tanto quanto quelli binari(e viceversa) fornendo una implementazione di semafori binari tramite i semafori ordinari e viceversa una implementazione di semafori ordinari tramite semafori binari. (l'invariante dei semafori binari si può anche scrivere 0 <= nV + Init - nP <= 1 dove nV + Init - nP rappresenta proprio il valore del semaforo).
Lezione del 11 novembre 2016
- Valore di ritorno di un processo
- Un processo ritorna un valore che è un numero intero.
- Questo può essere deciso come valore di ritorno del main, oppure con la funzione exit.
- La system call wait aspetta che lo stato di un processo figlio cambi e quando cambia scrive il nuovo in una variabile.
- Quando un programma termina il suo valore di ritorno viene salvato nel descrittore del processo. Se il padre non esegue la wait il descrittore del processo figlio non verrà mai eliminato e il processo figlio rimarrà uno "zombie".
- Un esempio del uso si queste system call si può trovare qui.
- Pipe
- La system call pipe crea un canale monodirezionale che può essere usato per la comunicazione tra processi. Dimostrazione del uso di pipe si può trovare qui.
- Lo zoo delle exec
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],char *const envp[]);
Spiegazione dei postfissi:
- l = elenco dei parametri passato tramite parametri a cardinalità variabile (variadic function)
- v = elenco dei parametri passato come array
- p = bisogna specificare il path completo dell'eseguibile
- e = bisogna specificare anche l'enviroment con cui verrà eseguito il programma. L'enviroment è una serie di variabili globali, tra cui il path. Il path è l'elenco dei percorsi dei programmi più usati.
Tutte queste funzioni alla fine sono solo delle interfacce per execve.
- Programmazione ad eventi
- E' un paradigma di programmazione dove il flusso del programma è determinato dal avverarsi di eventi. Il programmatore specifica il codice (Handlers) che deve essere eseguito al verificarsi di un certo evento.
- System call che sono utili per far questo sono select,pselect,poll,ppoll,epoll.
Lezione del 15 novembre 2016
- Differenza tra select,poll,pselect,ppoll e epoll
- La poll a differenza della select richiede un array di strutture pollfd invece che una bitmask. Permette di specificare precisi eventi per cui stare in ascolto.
- Le versioni con prefisso "p" implementano anche la gestione dei segnali.
- L'epoll è linux only. E' moderna (2002) e fornisce un file dove leggere direttamente quali file descriptor sono stati modificati in modo da non dover scorrere tutta la lista.
- Dimostrazione della equivalenza di potere espressivo fra semafori e semafori binari.
- I semafori implementati per dimostrare l'equivalenza possono essere trovati a questa pagina.
- Definizione di Monitor.
Un monitor è un costrutto ad alto livello per la sincronizzazione pensato ispirandosi alla programmazione ad oggetti.
E' una classe che incapsula la risorsa condivisa, la rende privata e permette di accedere a questa solo tramite metodi. Questi metodi implementano i meccanismi di sincronizzazione.
Uno solo processo può essere al interno del monitor e avere accesso ai dati protetti da mutua esclusione.
E' presente una coda di attesa per l'accesso al monitor.
Definiamo inoltre delle variabili condition.
Gli unici metodi che possono essere chiamati su una condition sono wait e signal. Ogni condition ha una propria coda di attesa
L'operazione wait sospende il chiamante e lo sposta nella coda di attesa della condition.
L'operazione signal risveglia un processo in attesa. Se non c'è nessun processo in attesa all'interno del monitor la signal fa entrare un eventuale processo in attesa di entrare nel monitor. Il chiamante di signal dopo aver risvegliato l'altro possibile processo deve mettersi in attesa per evitare che ci siano due processi in concorrenza al interno del monitor, ma invece di andare nella coda di attesa della condition viene messo in un urgent stack che ha più priorità rispetto alla coda esterna dei processi in attesa di entrare nel monitor.
Ricapitolando le strutture dati per un monitor sono una coda esterna per l'accesso al monitor, una coda interna (non accessibile da fuori ma non dentro la mutua esclusione) per ogni variabile condizionale e l'urgent stack.
- Implementazione dei Semafori tramite monitor.
Lezione del 18 novembre 2016
- File speciali a blocchi o a caratteri
- In Unix molte cose sono rappresentate come file. Per esempio i device come i terminali e le partizioni del disco sono file. Si chiamano file speciali ma non sono tanto differenti dai file comuni. Utilizzano anche gli stessi sistemi di protezione all'accesso. Si dividono i due categori:
- File speciali a blocchi: utilizzati maggiormente dai sistemi di storage tipo hard-disk e CD-ROMs. Se per esempio il blocco è di 1024 bytes allora possiamo scrivere e leggere con tale granularità, cioè non potremo mai scrivere soltato 500 bytes ma dovremo scrivere, appunto a "blocchi".
- File speciali a caratteri: utilizzati maggiormente per dispositivi di input-output tipo mouse,tastiera,terminali ecc.. permettono di lavorare con una granularità di 1 byte ma hanno un accesso sequenziale invece che diretto come i file a blocchi.
- Inoltre nei file speciali l'ampiezza è sostituita da 2 numeri, uno che indica il driver del dispositivo e l'altro le possibili parti del dispositivo, per esempio le partizioni.
- System call ioctl
- Ioctl serve per controllare dei device. Per esempio permette di fermare la testina di lettura del disco oppure far partire il motore del lettore CD. E' necessaria in quando si è voluto uniformare la lettura e scrittura di stream per tutti i device tramite le system call read/write ma chiaramente ogni dispositivo ha anche le sue diverse necessità e queste vengono soddisfatte da ioctl.
- Syscall
- Syscall è una funzione di libreria C che serve a chiamare system calls che non hanno una loro interfaccia per il linguaggi C. Per esempio getdents.
- System call e funzioni di libreria per directory
- Le directories sono sempre file ma si può fare l'accesso solo in lettura, per esempio per ottenere la lista di tutti i file e directory all'interno di quella directory.
- getdents legge un file directory ed è la system call principale, tutte le funzioni di libreria C tipo opendir,readdir,readdir_r(per multithread) chiamano getdents.
- Tutte queste funzioni lavorano con una struct dirent che rappresenta una directory entry.
- Si può usare anche scandir che è reetrant (nessun problema di race condition) e invece di leggere un elemento della directory per volta ritorna direttamente un array di tutti gli element allocato dinamicamente (occorre ricordarsi di deallocare con free tutti gli elementi e l'array stesso).
Lezione del 22 novembre 2016
Problema dei filosofi a cena risolto con i monitor. Soluzione con le condizioni associate alle "bacchette" e con le condizioni associate ai filosofi. discussione dei problemi di deadlock e starvation nell'implementazione tramite monitor.
Problema dei lettori e scrittori tramite monitor. Soluzione con privilegio ai lettori, agli scrittori e modifiche necessarie per la soluzione priva di starvation.
Lezione del 25 novembre 2016
Lezione del 29 novembre 2016
- Implementazione dei monitor tramite semafori
- Un soluzione simile a quella vista a lezione può essere trovata qui.
- Introduzione al message passing
- E' un altro modo per fare programmazione concorrente alternativo alla memoria condivisa che abbiamo visto fin ora.
- Se i programmi non condividono memoria ma devono sincronizzarsi per lavorare assieme hanno bisogno di scambiarsi messaggi.
- Per l'indirizzamento serve un sistema di naming, come il pid dei processi.
- Due primitive: send e receive. Nella receive come indirizzo da chi ricevere si può mettere una wildcard in modo da riceve da tutti.
- Nella send invece occorre indicare l'identificativo del destinatario (se si ammettesse di poter inserire una wildcard si spedirebbero messaggi in broadcast/multicast. E' una problematica più complessa che viene trattata nei corsi di sistemi distribuiti).
- Lo scambio di messaggi può essere:
- Sincrono: send bloccante e receive bloccante, senza memoria di supporto.
- Asincrono: send non bloccante e receive bloccante, con memoria di supporto. I messaggi spediti rimangono in una coda (di ampiezza massima illimitata nel modello).
- Completamente asincrono: send non bloccante e receive non bloccante. Poco utilizzato, il destinatario deve fare un polling per controllare se il messaggio è arrivato o no.
- Per dimostrare la stessa espressività dei metodi dobbiamo sempre creare delle librerie e non dobbiamo aggiungere nessun processo.
- La metodologia asincrona è espressiva almeno quanto quella sincrona mentre non è vero il contrario.
- Per creare un metodo sincrono con chiamate asincrone basta bloccare il programma finché non si riceve un acknowledgement.
- Invece per creare un metodo asincrono con chiamate sincrone bisogna aggiungere un processo e quindi questo dimostra che non sono equivalentemente espressive.
- Soluzioni di esercizi d'esame
- Problema della lavatrice
- Problema del ponte a senso unico
Lezione del 2 dicembre 2016
- Implementazione della libreria per message passing
- I sorgenti della implementazione possono essere trovati qui
- I segnali
- I segnali sono un metodo di comunicazione tra processi utilizzato in UNIX.
- Ogni segnale è rappresentato da un numero. Per esempio "segmentation fault" è il numero 11.
- La system call kill() serve per inviare un segnale. signal() serve per definire l'handler, una funzione che viene eseguita quando il processo riceve uno specifico segnale.
- Ogni segnale ha il suo handler di default e tramite signal() noi sovrascriviamo il default handler.
- Permesso setuid
- Permette a dei programmi di eseguire operazioni che hanno bisogno dei permessi di root. L'attributo setUserId attivato vuol dire che il programma verrà eseguito con i privilegi del possessore del file piuttosto di quelli di chi lo esegue.
- Proposta di soluzione esercizio 4 del Coding Contest 25 novembre 2016
Lezione del 6 dicembre 2016
- Implementazione di un servizio di Message Passing Asincrono dato uno sincrono (con processo server).
- Implementazione di un servizio di Message Passing completamente asincrono dato uno sincrono.
- Analisi del potere espressivo dei servizi di message passing.
- kernel monolitici e microkernel
- macchine virtuali a livello di processo e a livello di sistema
I sorgenti degli esperimenti con il message passing sono in questo file.
Lezione del 9 dicembre 2016
- Il problema della Cena dei filosofi con il message passing (asincrono)
- Buffer Limitato con message passing (asincrono).
Lezione del 13 dicembre 2016
La lezione TACE per malattia (influenza) del docente.
Lezione del 16 dicembre 2016
- Specifiche del progetto fase uno
Il documento delle specifiche può essere trovato qui.
- List.h
- Lista dei processi
- Coda dei thread
- Code dei messaggi
- Autotools
- Insieme di strumenti per la generazione automatica di Makefiles.
- comando autoreconf per generale il file configure
- ./configure per generare makefile.
Lezione del 21 febbraio 2017
Argomenti trattati:
- Visione a strati di un elaboratore
- Gli strati sono livelli di astrazione. Ogni strato deve "parlare" il linguaggio del livello sottostante e deve fornire un proprio linguaggio ai livelli superiori.
- Per esempio il sistema operativo parla l'ISA del livello hardware e fornisce alle applicazioni le system call. Il sistema operativo maschera il livello hardware in quanto fornisce la possibilità alle applicazioni di utilizzare istruzioni ISA ma non tutte, per ragioni di sicurezza.
- Componenti fondamentali di un sistema operativo
- A sua volta il sistema operativo può essere visto come un insieme di strati. Esistono sistemi operativi a singolo strato (come MS-DOS) e più strati (layered).
- Le parti principali in cui possiamo suddividere un sistema operativo sono:
- Lo scheduler
- Il memory manager
- Il file system
- L'I/O manager
- Il networking manager
- Di questa lista, gli elementi assolutamente fondamentali per considera un programma un sistema operativo sono lo scheduler e una parte essenziale del memory e I/O manager.
- Il networking e file manager si appoggiano al I/O manager per svolgere i loro compiti.
- Bootstrap
- Letteralmente "mettersi in piedi tirandosi dai lacci degli stivali", nel senso di attivarsi senza aiuto esterno. All'accensione il computer legge da una ROM le prime istruzioni necessarie. Viene sempre letto dai primi settori della memoria di massa il bootloader. :Il bootloader (per esempio GRUB) conosce già molti filesystem, ma non abbastanza. Il bootloader carica un file system temporaneo apposito chiamato initrd per caricare i moduli necessari al kernel.
- Come rappresentiamo i processi
- Dobbiamo sia tener conto a che punto siamo arrivati nell'esecuzione del processo sia tener conto delle risorse di cui il processo è detentore.
- Utilizziamo la struttura Process Control Block (task_struct in linux) per i processi e "Thread Control Block" (task_struct in linux) per i thread.
- Process control block:
- PID (Process ID)
- PPID (Parent Process ID) per poter creare una gerarchia di processi
- punti di accesso alla memoria (codice,dati,tabella di rilocazione,paginazione)
- lista dei thread
- owner (se il sistema è multiuser)
- Risorse del processo
- Coda dei messaggi per IPC (Inter-Process Communication)
- accounting (tempo di esecuzione sia in modalità kernel sia in modalità user)
- valore di ritorno del processo
- Thread control block:
- TID (Thread ID)
- stato del processore
- call stack
- ready/running/waiting
- Avvicendamento dei processi
- Definizione di avvicendamento: Successione prevista o regolata nel tempo, alternanza.
- I context switch avvengono a seguito di trap/interrupt.
- Il ciclo di vita di un processo passa tra gli stati ready, running, waiting e infine term.
- Lo scheduling (processo decisionale) può venire applicato nelle seguenti 4 situazioni:
- Quando un processo passa dallo stato di running a quello di waiting
- Quando un processo passa dallo stato di running a quello di ready
- Quando un processo passa dallo stato di waiting a quello di ready
- Quando un processo passa dallo stato di running a quello di term
- Se lo scheduling avviene solo nella situazione 1 e 4 allora si utilizza un metodo non preemptive. Dal momento che la CPU è allocata a un processo questo la detiene finchè non termina o entra di sua spontanea volontà in stato di waiting. La CPU non può decidere di far aspettare un processo spostandolo temporaneamente nella coda dei processi ready. Questo sistema era utilizzato da vecchi sistemi operativi come Windows 3.x e dalle versione di Mac OS prima della versione X.
- Nel preemptive scheduling invece la CPU può decidere di sospendere un processo, questo può creare race condition ma anche un sistema più equo di distribuzione delle risorse. Le race condition vengono risolte con i metodi che abbiamo visto nel primo semestre.
'
Lezione del 23 febbraio 2017
System call
Abbiamo analizzato le system call che erano già presenti nella versione 6 di Unix (1975).
Le abbiamo poi confrontate con quelle attuali del Il_''catalogo''_delle_System_Call.
Shell Scripting
Gli script vengono utilizzati per lanciare un demone, guardare i processi, etc. Anche l'amministrazione di sistema avviene tramite scripting. Ad esempio, dopo il boot, il processo init avvia le funzionalità di sistema tramite script.
Unix unifica l'idea di script con quella di shell. La shell è un processo che interagisce con l'utente. In Unix la novità introdotta è rappresentata dalla presenza di un linguaggio che riguarda i comandi, utile per scrivere gli script per la shell.
Come indichiamo quale shell usare? Scrivendo nella prima riga #! seguito dal path e dal nome della shell. Il kernel prende ciò che è scritto nella prima riga e lo esegue per interpretare lo script. Nell'esempio sottostante Script è un commento perchè è preceduto da #.
ESEMPIO
#!/bin/bash #Script
echo "Hello World!"
Per scrivere script abbiamo bisogno di variabili. Nelle shell queste possono essere di 2 tipi:
- Locali: viste solo dalla shell, non perturbano comportamento dei processi.
- D'ambiente: recepita dai comandi come ambiente.
ASSEGNAMENTO E VARIABILI
ESEMPIO 1
a=2 /* Non devono esserci spazi!!! a = 2 doesn't work */
echo $a /* Stampa 2 */
echo ${a}a /* Stampa 2a */
ESEMPIO 2 - Nuova shell
bash /* Apro nuova shell */ echo $a /* Stamperà una riga vuota perchè la var. a non è locale della nuova shell */ exit /* chiudo nuova shell */
ESEMPIO 3 - Esportare variabile locale
export a /* La var. a diventa variabile d'ambiente */ bash echo $a /* Ora possiamo chiamare la var. a perchè è diventata d'ambiente */
ESEMPIO 4 - csh
csh in molti casi dovrebbe già essere installato di default. Se non è così è possibile installarlo eseguendo
sudo apt-get install csh
csh /* Apro cshell, noterete il simbolo di percentuale % a inizio riga di comando */ set a=42 /* assegnamento */ csh /* apro nuova shell */ echo $a /* non possiamo chiamare a(42) perchè locale alla prima shell, viene chiamata a d'ambiente se presente */ exit setenv a 42 /* Per creare una variabile d'ambiente, da notare la mancanza di = */ csh echo $a
ARGOMENTI
Negli script possiamo avere degli argomenti. Vengono visti come $1, ..., $9, ${10}, etc. $* indica tutti gli argomenti
ESEMPIO 1
#!/bin/bash echo $* /* Richiama tutti gli argomenti */ echo $1 $2 /* Richiama solo i primi due argomenti */ shift /* Sposta la riga di comando degli argomenti di una posizione verso sx */ echo $*
Una volta salvato il file con estensione .sh, eseguire da terminale:
chmod +x nomefile.sh ./nomefile.sh arg1 arg2 ...
Se passiamo come argomenti: uno due tre quattro, l'output sarà:
uno due tre quattro uno due due tre quattro
A volte dobbiamo proteggere dei caratteri. Alcuni di essi possono essere delle wildcard. Ci sono 3 modi per proteggerli:
\* '*' "*"
Analizziamone le differenze tramite un esempio.
ESEMPIO 1
echo \* // OUTPUT: * echo '*$a' // OUTPUT: *$a echo "*$a" // OUTPUT: *2
Nel primo caso l'escape vale solo per *. Nel secondo caso vale per tutta la stringa. Nel terzo caso vale per * e richiama la variabile.
ESEMPIO 2
echo ab // OUTPUT: ab echo "ab" //OUTPUT: ab echo a b //OUTPUT: ab <-- non rileva gli spazi echo "a b" //OUTPUT: a b
Lezione del 28 febbraio 2017
Argomenti trattati:
- Ciclo di vita di un kernel
- Dopo l'inizializzazione (Creazione di code, rilevazione di device, ecc..) si crea a "mano" il primo processo.
- L'esecuzione dello scheduler si alterna a quella dei processi. Quando un processo utente viene eseguito il kernel non ha più il controllo del flusso e gli viene restituito solo quando avviene un interrupt/trap.
- Parametri di valutazione di un algoritmo di scheduling
- % Utilizzo CPU: Bisogna cercare di tener utilizzata il processore il più possibile riducendo i momenti di inutilizzo (idle).
- Produttività (Throughput) Numero di processi completati per unità di tempo
- Tempo totale (turnaround time) Tempo totale impiegato dall'esecuzione del processo al completamente. Tiene conto del tempo speso in attesa oltre al tempo in esecuzione.
- Tempo di risposta: Tempo prima che un primo output venga generato dal momento in cui il processo viene eseguito. In un sistema interattivo è importante per non dare all'utente l'idea di malfunzionamento.
- Tempo di attesa. Non aspettando l'I/O ma bensì tempo speso nella ready queue.
- Processi CPU Bound e I/O Bound
- I processi si possono dividere in queste due categorie. I processi che utilizzano il processore per tempi più lunghi (per esempio quelli di calcolo scientifico) si chiamano CPU Bound mentre quelli che richiedono spesso interazioni e si fermano ad aspettare l'I/O si chiamano I/O Bound. Algoritmi di scheduling differenti possono favorire o sfavorire una delle due categorie. L'obbiettivo e trovare un algoritmo che sia ottimale per tutti i processi.
- Algoritmi di scheduling
- First come first served
- Lo scheduler implementa una semplice coda dei processi che hanno richiesto l'esecuzione. E' semplice da capire e creare ma il tempo medio di attesa per un processo può essere lungo. Dipende molto dall'ordine in cui vengono avvicendati processi CPU bound e I/O Bound. Un processo CPU bound può creare un effetto convoglio e far dipendere il tempo di attesa di altri processi che sono I/O bound al suo tempo di esecuzione. Questo algoritmo non è quindi equo.
- Shortest job first
- Forse più correttamente nominato algoritmo shortest next CPU burst. Ad ogni processo viene associato il suo tempo di esecuzione e viene scelto dalla ready queue sempre il processo con il tempo più basso. Per determinare il tempo di esecuzione a priori si utilizza una media esponenziale dei tempi di esecuzione dello stesso processo nel passato.
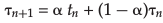 t sono le misurazioni recenti mentre 'tau' sono la storia più remota. Il parametro alfa determina quanto la media esponenziale sia basata sulla storia recente o su quella passata.
t sono le misurazioni recenti mentre 'tau' sono la storia più remota. Il parametro alfa determina quanto la media esponenziale sia basata sulla storia recente o su quella passata.
- Shortest remaining time first
- SJF può essere preemptive oppure no. Nel caso preemptive prende il nome di Shortest remaining time first. Se un processo A è in esecuzione e arriva un'altro processo B con tempo di esecuzione minore allora A viene fermato e viene eseguito B. La priorità di A nella coda è ora il tempo stimato rimanente.
- Round robin
- E' definita un unità di tempo, di solito tra i 10 e i 100 millisecondi, e ogni processo ha un tempo massimo di esecuzione pari a questa unità. I processi vengono avvicendati a turno in una coda. Un processo termina l'esecuzione o per sua volontà (il tempo rimasto del quanto di tempo non è considerato) oppure perchè è scattato l'interval timer. Nell'ultimo caso il processo viene inserito in coda come se fosse un processo appena arrivato. La performance di questo algoritmo dipendono molto da che tipi di processi si gestiscono e dalla dimensione dell'unita di tempo. Se questa è larga allora l'algoritmo è più simile a FCFS mentre un'unita di tempo piccola porta a più context switch e quindi a più overhead. L'unità di tempo andrebbe decisa in proporzione al tempo di context switch.
- Scheduling a priorità
- Ad ogni processo è assegnata una priorità che si riflette nella priorità che ha il processo nella ready queue.
- La priorità di un processo può essere influenzata da fattori interni (come i requisiti di memoria) o esterni al sistema operativo (come l'importanza di un processo). L'algoritmo può essere non preemptive o premtive, nel caso in cui interrompa il processo attuale se arriva un processo con più priorità.
- L'SJF può essere visto come un caso particolare di scheduling a priorità, in cui la priorità e appunto inversamente proporzionale al tempo di esecuzione.
- Un problema dello scheduling a priorità è la starvation, che può essere risolta con il meccanismo di aging in cui un processo aumenta di priorità proporzionalmente al tempo cui rimane nella ready queue.
- Scheduler multilivello
- Questo è lo scheduler più completo in quanto divide i processi in gruppi e utilizza differenti algoritmi per ogni gruppo.
- Una tipica suddivisione è quella di processi foreground e background, rispettivamente I/O bound e CPU bound. Per ogni gruppo viene creata una coda apposita.
Lezione del 2 marzo 2017
Shell Scripting
'$' seguito da caratteri esegue una sostituzione, questa può essere:
ESEMPIO 1 (contenuto)
echo $SHELL
echo $USER
ESEMPIO 2 (comando)
echo $ls
ESEMPIO 2.1
du -s $(ls -d *es) //du -s prende come input l'output del comando compreso tra parentesi tonde
ESEMPIO 3 (wildcard)
echo * // tutti file/dir echo *es // file/dir che terminanon con es echo *[lg]es // file/dir che terminanon con les/ges echo ????? // file/dir con 5 caratteri
Queste wildcard servono per poter individuare insiemi di file in un colpo solo.
ESEMPIO 4 ($ come sintassi riconosciuta da grep)
grep '>$' *.c // trova tutte le linee che terminano con '>' all'interno dei file .c
ESEMPIO 5 (PID)
echo $$ // restituisce PID dello script nel quale viene eseguito
ESEMPIO 6a
echo $1 $2 $3 >/tmp/tmpscript //scrive i 3 argomenti in tmpscript cat /tmp/tmpscript //lettura tmpscript rm -f /tmp/tmpscript //rimozione tmpscript
Se cerchiamo di lanciare quasi contemporaneamente lo script dell'esempio 6 in due shell differenti, lo script non funziona perchè lavorano sullo stesso file. Possiamo quindi ricorrere all'utilizzo di $$.
ESEMPIO 6b
echo $1 $2 $3 >/tmp/tmpscript$$ sleep 3 //in modo da poter lanciare lo script in un'altra shell cat /tmp/tmpscript$$ rm -f /tmp/tmpscript$$
ESEMPIO 7
grep bash myscript.sh >& dev/null //ridireziono l'output di grep sul "null device" echo $? //restituisce 0 se il comando precedente è stato eseguito correttamente, 1 altrimenti
Gli operatori >> e <<
>> è simile a > ma scrive alla fine del file invece che all'inizio.
<< serve invece per inserire l'input di un comando direttamente nello script, come mostrato nel successivo esempio della mail.
ESEMPIO 8 (script per inviare mail)
#!/bin/bash mail $1 << ENDOFMESSAGE ciao $1 questa è una mail di prova ENDOFMESSAGE //etichetta usata per indicare il termine del messaggio
Con
echo $1; echo $2; ls
raggruppiamo una sequenza di comandi sulla stessa riga
ESEMPIO 9((|| &&)
Gli operatori || e && possono essere utilizzati per processare più comandi consecutivamente.
command || die
gcc -o hwx hw.c && ./hwx
ESEMPIO 10 (sottoshell)
Una lista di comandi all'interno di () viene eseguita in una sottoshell. Le variabili all'interno della sottoshell non sono visibili al di fuori del blocco di codice nella sottoshell. Sono variabili locali.
(cd subdir; ls) //eseguo un comando in un'altra directory
Pushd e popd
Simili al comando cd ma pushd inserisce i percorsi visitati in una pila e tramite popd e possibile ripercorrere a ritroso le directory visitate.
ESEMPIO 11 (background jobs)
ping google.com & //esegue ping in background jobs //mostra la lista dei jobs in esecuzione //poniamo che l'output di jobs sia "[1]+ In esecuzione ping google.com &" kill -9 %1 //termina il processo con identificatore 1
bg repristina un processo fermato con CTRL+Z.
fg riporta in primo piano un processo mandato in background.
test e type
test serve a comparare valori e controllare il tipo dei file.
la sintassi [] è un alias di test.
if [ $$ -eq '10853' ] ; then echo "il processo corrente ha pid 10853"; else echo "il processo corrente non ha pid 10853"; fi; //che è equivalente a if test $$ -eq '10853'; then echo "il processo corrente ha pid 10853"; else echo "il processo corrente non ha pid 10853"; fi;
type invece mostra l'origine di un comando, se sono integrati nella shell oppure è un programma a parte.
Switch Sintassi degli switch in bash.
case expression in
pattern1 )
statements ;;
pattern2 )
statements ;;
...
esac
Comando cron
cron serve per eseguire operazioni pianificate. Gli script in /etc/init.d vengono eseguiti automaticamente da cron.
xarg
xarg permette di eseguire un comando passandogli come parametri i valori letti da standard input.
uniq
uniq può essere usato per trovare e eliminare righe duplicate.
wc
wc crea il word count di un file. Non conta solo le parole ma anche i caratteri e le righe.
diff e patch
Il comando diff può essere utilizzato per mostrare le differenze tra due file testuali. E' utilizzato internamente da git.
Patch serve per applicare un diff file a un altro file in modo da aggiornarlo.
Lezione del 7 marzo 2017
Una risorsa è ogni elemento utile all'elaborazione.
- Classificazione di risorse
- Fisiche e logiche
- Esempi:
- CPU, memoria e dispositivi sono risorse fisiche.
- file, strutture dati, critical section sono risorse logiche.
- Fungibili
- Una risorsa è fungibile se è uguale prendere un bene o un'altro se sono dello stesso tipo. Richiedere un area di memoria o un altra è indifferente se tutte e due soddisfano i requisiti del processo. Richiedere file o dispositivi differenti invece cambia.
- Assegnazione statica o dinamica
- L'assegnazione statica prevede che una risorsa sia monopolio di un processo.
- Accetta richieste multiple o solo singole
- Se può ricevere richieste d'uso da più processi e memorizzare/servire contemporaneamente le richieste oppure no.
- condivisibili e non condivisibili
- Un file in lettura è una risorsa condivisibile, più processi possono accedere contemporaneamente. Un file in scrittura invece è una risorsa non condivisibile perché potrebbe capitare una race condition.
- bloccante e non bloccante
- Se l'accesso alla risorsa implica dei tempi di attesa relativamente lunghi al processo, la risorsa è da considerarsi bloccante.
- prelasciabile o non prelasciabile
- Il processo può rilasciare in qualsiasi momento la risorsa e permetterne l'uso ad un altro processo? Una stampante è un esempio di risorsa non prerilasciabile.
- Deadlock
- Un deadlock può avvenire in presenza di risorse bloccanti, non condivisibili, non prerilasciabili e con una situazione di attesa circolare.
- detection: grafo di Holt
- I grafi di allocazione delle risorse, introdotti da Holt nel 1972 sono un buon modo per descrivere lo stato di un sistema e prevedere possibili deadlock. Ogni nodo rappresenta una risorsa o un processo. Di solito le risorse sono rappresentate da quadrati e i processi da cerchi. Un arco da un processo a una risorsa significa che quel processo ha richiesto un'istanza della risorsa. Un arco da una risorsa a un processo vuol dire che un'istanza di quella risorsa è stata assegnata al processo.
- teorema dei cicli in grafi di Holt con un solo tipo di risorsa
- Se il grafo non contiene cicli allora di sicuro non possono esserci deadlock.
- Se il grafo contiene un ciclo allora può esserci un deadlock.
- Se le risorse coinvolte in un ciclo hanno solo un'istanza o ogni loro istanza e coinvolta in un ciclo allora c'è di sicuro un deadlock.
- Questo tecnica di permette di analizzare uno stato attuale di un sistema, ma dobbiamo trovare un modo per prevedere lo stato futuro del sistema e quindi prevedere i deadlock.
- processo di riduzione
- Per vedere lo stato di un sistema futuro possiamo usare un processo di riduzione del grafo di allocazione delle risorse.
- Se una risorsa allocata a un processo può essere data dopo un certo periodo a un altro processo che l'ha richiesta allora si può fare una riduzione. Una riduzione consiste nell'eliminare un arco risorsa-processo perchè quel processo ha finito di utilizzare la risorsa oppure è stata prerilasciata e invertire un arco processo-risorsa di un processo che aveva richiesto la risorsa in un arco risorsa-processo.
- Se un grafo può essere ridotto per tutti i suoi processi allora non può esserci deadlock.
- Il problema di questo metodo/algoritmo è che nel momento che deallochiamo una risorsa a un processo e più processi avevano richiesto quella risorsa come scegliamo deterministicamente a quale processo assegnare la risorsa? Dovremmo provare tutti i casi per accertarsi che non si crei deadlock, ciò significa fare backtrack e perdere la polinomialità dell'algoritmo.
- definizione di Knot
- Il Knot è una caratteristica di un grafo che si verifica velocemente e permette di determinare possibili deadlock.
- Un knot è un insieme di nodi in cui, per ogni nodo del knot, tutti e solo i nodi del knot sono raggiungibili da quel nodo.
- Un knot è una condizione sufficiente ma non necessaria per i deadlock. Ciò vuol dire che possono capitare deadlock anche senza la presenta di un knot.
- teorema dei knot nei grafi di Holt con più tipi di risorse
- Dato un grafo di Holt con una sola richiesta sospesa per processo.
- Il grafo rappresenta uno stato di deadlock solo se esiste un knot.
- prevention
- Se il sistema cerca di non far verificare almeno una delle condizioni necessarie al deadlock allora questo non si verificherà mai.
- Questo però comporta anche sottoutilizzo delle risorse del sistema.
- avoidance
- Condizione di safety
- Un sistema è in una condizione di safety se esiste una safe sequence.
- Una safe sequence è una sequenza di processi dove per ogni richiesta di risorse di un processo questa richiesta può essere soddisfatta con le richieste disponibili al momento più tutte le risorse allocate precedentemente ai precedenti processi della sequenza.
- Finchè c'è safety non possono verificarsi deadlock. In una situazione unsafe non è detto che capiti deadlock, ma è possibile.
- algoritmo del Banchiere (mono e multivaluta).
- L'algoritmo del banchiere si basa sul fatto che una banca non dovrebbe mai rimanere senza denaro da prestare ai clienti.
- Vengono mantenute varie strutture dati come il capitale iniziale della banca, quanto è disponibile in cassa, quanto è stato prestato ad ogni cliente e quanto si può ancora prestare ad ogni cliente (in base al credito che ogni cliente ha).
- La condizione di safety è data dalla condizione che bisogna mantenere almeno uno dei clienti soddisfacibile cioè che il denaro in cassa sia maggiore del possibile richiesta di prestito di almeno un cliente.
- Se questa condizione non si verificasse alloca il banchiere deve aspettare che un cliente restituisca il prestito.
- In caso di più valute (yen, dollari, euro, ...) che rappresentano i tipi diversi di risorse del sistema. Tutte le strutture dati aumentano di una dimensione, per esempio il denaro iniziale diventa un vettore.
- Teorema: il processo di controllo di safety non ha necessita' di backtrack.
- Tecnica dell'ostrica/struzzo
- Un altro modo per gestire i deadlock e quello di ignorarli completamente.
- La maggior parte dei sistemi operativi utilizza questo metodo.
- Soprattuto in sistemi in cui è statisticamente determinato che i deadlock si verificano poco frequentemente i sistemi di prevenzione e avoidance costituirebbero un overhead troppo elevato.
- Sta allora alle singole applicazioni evitare di crearli.
Lezione del 9 marzo 2017
- awk
- phase2: prime fasi del boot
- python: presentazione del linguaggio ed analisi delle caratteristiche
Lezione del 14 marzo 2017
Gestione della memoria
- Binding a tempo di esecuzione, compilazione o esecuzione
- Memory Management Unit (MMU)
- Allocazione statica o dinamica
- Allocazione continua o non contigua
- Metodo delle partizioni fisse
- Problema della frammentazione interna.
- Metodo delle partizioni variabili
- Problema della frammentazione esterna.
- Algoritmi di scelta dell'area di allocazione
- First fit
- Best fit
- Worst fit
- Next fit
- Paginazione
- Segmentazione
- Memoria virtuale
- Algoritmi di scelta dell'area di allocazione
Lezione del 16 marzo 2017
- Progetto phase2: analisi del manuale di uARM
- Python: funzioni, oop, @memoize, @trace
Lezione del 21 marzo 2017
La lezione del 21 marzo tace per impegno del docente.
Lezione del 23 marzo 2017
Memoria virtuale:
Algoritmi di paginazione:
Quando avviene un page fault serve un algoritmo per trovare la pagina "meno utile" in memoria a cui sostituire la pagina richiesta.
- FIFO viene sostituita la pagina che da più tempo è in memoria
- LFU Least Frequently Used contando il numero di richieste alla pagina possiamo calcolare quali sono le pagine più richieste e tenere solo quelle in memoria. Il problema è che una pagina potrebbe essere richiesta molto in una fase iniziale di un processo, quindi avere un rank elevato, però poi non essere più utilizzata. Una soluzione a questo problema è quella di shiftare a destra di 1 i bit del contatore degli utilizzi a intervalli regolari, ponendo questo in un decadimento esponenziale.
- LRU Least Recently Used si sostituisce la pagina che non è stata utilizzata da più tempo.
- Algoritmo ottimo algoritmo teorico utile per fare benchmark degli altri algoritmi. Se conosciamo a priori la reference string una sequenza che indica quali saranno le richieste delle pagine nel futuro, possiamo sostituire le pagine che per più tempo non saranno richieste, riducendo al minimo i page fault.
Anomalia di Belady Abbiamo dimostrato che l'algoritmo FIFO all'aumentare della memoria può peggiorare di performance.
Lezione del 28 marzo 2017
Algoritmo second chance o dell'orologio
Linking statico
Loading dinamico
Memoria secondaria
Algoritmi di scheduling delle seek
- FIFO
- SSF
- c-look
Lezione del 30 marzo 2017
Discussione sulle specifiche del progetto
- Creazione pagina Specifiche_phase_2_2016/17
Python standard library
- libreria sys: Permette di prendere parametri da linea di comando. Si utilizza sys.argv.
- libreria os: Permette di navigare nella gerarchia di directory con os.walk.
Lezione del 4 aprile 2017
RAID
(Redundant Array Inexpensive/Independent Disks)
l’idea principale nasce per ottenere maggiori performance (raid 0 ed 1), non maggiore affidabilità (raid 4 e 5).
- RAID0 (Striping): i dischi sono posti in sequenza.Vengono create le stripe, sequenze di bit che sono posti su n dischi sequenzialmente. Lo striping può essere a vari livelli, a livello di bit, di byte, di settore o di blocco. Quello più utilizzato e il livello di blocco. Cioè per scrivere un file che è composto da più blocchi si suddividono i blocchi in più dischi. Attenzione, file piccoli potrebbero sostare su una sola stripe, quindi su un solo disco.
- Il miglioramento di performance si paga in maggiore faultness. dipende dal costo dei dati salvati.
- RAID1 (mirroring): ogni disco ospita la copia dei dati. doppia velocità in lettura (teoricamente). Stessa velocita di scrittura.
- Size = ½ readSpeed = N wSpeed = ½ N FT = 1
- RAID10 = 1+0 striping su 2 mirror.
- RAID 2-3 (deprecated):Agisce sui singoli blocchi i dati vengono salvati in maniera sincrona con meccanismi di parità (hoffman per correzione di errori nel RAID2, ciclica per RAID3).
- RAID4: usa dischi normali, non agisce su singoli blocchi ma su stripe ampi.
parityMap = S0 XOR S1 XOR S2 XOR S3 (in caso di 4+1 dischi).
nel caso si rompa S4, i dati non avranno problemi. Se si rompesse un qualunque dei primi 4 dischi, basterà effettuare lo XOR degli altri e copiare tali dati su un nuovo HD.
S1 rotto. new_S1 = S0 XOR S2 XOR S3 XOR P0123 Sopporta una sola rottura.
Per aggiornare il disco di parità in caso di modifica a S2 (chiamato ora S2’)
P0123 = P0123 XOR S2 XOR S2’. il primo xor toglie il valore da P0123 di S2, il secondo XOR aggiunge il valore S2’. in questo modo, aggiorno solo 2 dischi, e uso gli stessi in lettura per ricalcolare la parità.
Le parità ciclano su tutti i dischi. Esistono controller che effettuano RAID5, oppure e’ possibile ottenere le funzionalità raid via sistema operativo.
- RAID5:
- Senza fault
- Size = N-1/N, rspeed=(N-1), wspeed=(N-2), FT=1
I dischi RAID soffrono alquanto in caso di terremoti.
File System:
Servizio per dare una interfaccia più comoda e generale per l’accesso alla memoria secondaria.
Nasce come informatizzazione delle pratiche di ufficio. le pratiche sono salvate in folders, fascicoli, poste poi nelle directories. come visualizzo questa struttura per l’utente? E ad i programmatori? come viene implementato?
Nasce l’idea di “aprire” i file. Nell'accedere da un programma ad il file-system (operazione non banale) si preferisce chiamare un’operazione di apertura, e utilizzare un descrittore al file per agire sul file richiesto.
La struttura di file/folder/directories possono inoltre supportare le astrazioni di condivisione e proprieta’. Tutti i controlli sono effettuati sono in fase di apertura (in modo da migliorare le performance).
Quali attributi caratterizzano un file?
- Name,
- Type,
- Location,
- Size,
- Ownership,
- Protection,
- Time stamp
UNIX opta per una scelta minimalista. Tutti i file sono stringhe di byte. AFS (Apple) da un tag di tipo e di creator per ogni file
maggiore e’ il numero di tipi di file, maggiore supporto per essi, ma piu’ codice nel kernel. I suffissi possono indicare ad altri programmi il tipo.
Semantica della coerenza vs Semantica delle sessioni (Andrew File System)
Per quali motivo vengono create le partizioni? /var andrebbe in una nuova partizione per un fattore di sicurezza.
Cosa c’e’ effettivamente sul disco? Una sequenza di blocchi, il cui primo (boot block) ha spazio per il bootloader e la tabella delle partizioni (MBR), con 4 elementi. 4 record che indicano dove ogni partizione inizia e finisce. Si possono usare partizioni estese, usando le prime 3 e nella quarta tutto il resto.
Ogni partizione ha all'inizio un BootRecord. L’ultima partizione contiene nel BootRecord le altre partizioni. GBT consente di avere un numero arbitrario di partizioni.
Raizer FS,
Read only file systems.
Initrd, ISO9660.
Quando si costruisce l’immagine, in realtà si sta creando il file-system ISO9660.
Come gestire invece file che possono cambiare? Allocazione indicizzata (a lista): creo un (o vari) blocco/i degli indici che punta ad i blocchi dati. l’accesso diretto cresce come il logaritmo dell’ampiezza. Allocazione concatenata (ad albero): (in fondo al blocco indico il successivo). Gestisce bene la dinamicità. Non piace perché’ non é per nulla efficiente l’accesso diretto.
Quali allocazioni usano i filesystem reali oggi?
fat: concatenata. I blocchi tengono solo i dati, esiste una file allocation table (vettore) che indica il prossimo blocco. I puntatori sono tutti vicini e quindi ponendo il vettore in cache, abbiamo disponibili diversi puntatori.
BerkleyFastFileSystem (progenitore dei EXT4…) usano allocazione indicizzata. Nasce per garantire performance ad i file piccoli. Nel descrittore del file (iNode) avra’ N (13 attualmente) puntatori. Uno, il numero 10, ad i blocchi, uno (11) indiretto alla tabella, uno (12) come duplice indiretto e il 13esimo come triplice indiretto.
I file hanno quindi una lunghezza massima. EX4 pero’ risolve indicizzando non i singoli blocchi ma le serie.
Gestione spazio libero
nella struttura indicizzata serve una struttura per tenere conto degli spazi liberi. Si puo’ usare una bitmap per tenere la contabilità degli spazi liberi e quelli utilizzati.
Lezione del 6 aprile 2017
File System. Ext2 e VFAT. Sicurezza, principi generali.
Lezione del 11 aprile 2017
Sicurezza: crittografia (chiave pubblica/chiave segreta) autorizzazione autenticazione firma elettronica. Virus Worm Cavalli di Troia.
Attacchi buffer overflow e toctou.
Lezione del 20 aprile 2017
(tace per impossibilita' del docente)
Lezione del 27 aprile 2017
P2test (prestest2).
DIscussione specifiche.
Lezione del 2 maggio 2017
Lezione del 4 maggio 2017
- Discussione su proposta da parte degli studenti di modifiche al test di progetto
- Soluzione all'esercizio C1 del 2014-06-16 (Monitor)
- Soluzione all'esercizio 1 del [2016-05-20] ( C )
- Soluzione all'esercizio 2 del 2008-06-13 (Dimostrazione algoritmo di rimpiazzamento a stack)
- Soluzione all'esercizio 1 del [2013-07-19] (Monitor)
Lezione del 9 maggio 2017
- Esercizio 2 prova teorica 2014.09.24
- Esercizio g.1 prova teorica 2013.07.19
- Esercizio c1 e c2 prova teorica 2015.01.20(2014.01.20)
- Esercizio c2 2013.05.30
Lezione del 11 maggio 2017
Lezione del 16 maggio 2017
- Chiarimenti su svolgimento esame
- Commenti su recenti eventi (WannaCry)
- Visione di programma python per costruzione di stringhe palindrome con monitor
- Correzione esercizio g2 prova teorica 20170209
- Correzione esercizio 1 Prova pratica 2016.09.13
- Esercizio c2 prova teorica 20140122